
Taxonomie de Flynn
(Redirigé depuis Taxinomie de Flynn)
La taxonomie de Flynn est une classification des architectures d'ordinateur, proposée par Michael Flynn en 1966[1],[2]. Les quatre catégories définies par Flynn sont classées selon le type d'organisation du flux de données et du flux d'instructions.
Type de classes[modifier | modifier le code]
- SISD (unique flux d'instructions, unique flux de données)
- Il s'agit d'un ordinateur séquentiel qui n'exploite aucun parallélisme, tant au niveau des instructions qu'au niveau de la mémoire. Cette catégorie correspond à l'architecture de von Neumann.
- SIMD (unique flux d'instructions, multiples flux de données)
- Il s'agit d'un ordinateur qui utilise le parallélisme au niveau de la mémoire, par exemple le processeur vectoriel.
- MISD (multiples flux d'instructions, unique flux de données)
- Il s'agit d'un ordinateur dans lequel une même donnée est traitée par plusieurs unités de calcul en parallèle. Il existe peu d'implémentations en pratique. Cette catégorie peut être utilisée dans le filtrage numérique et la vérification de redondance dans les systèmes critiques.
- MIMD (multiples flux d'instructions, multiples flux de données)
- Dans ce cas, plusieurs unités de calcul traitent des données différentes, car chacune d'elles possède une mémoire distincte. Il s'agit de l'architecture parallèle la plus utilisée, dont les deux principales variantes rencontrées sont les suivantes :
- MIMD à mémoire partagée
- Les unités de calcul ont accès à la mémoire comme un espace d'adressage global. Tout changement dans une case mémoire est vu par les autres unités de calcul. La communication entre les unités de calcul est effectuée via la mémoire globale.
- MIMD à mémoire distribuée
- Chaque unité de calcul possède sa propre mémoire et son propre système d'exploitation. Ce second cas de figure nécessite un middleware pour la synchronisation et la communication.
Un système MIMD hybride est l'architecture la plus utilisée par les superordinateurs. Ces systèmes hybrides possèdent l'avantage d'être très extensibles, performants et à faible coût.
Diagramme de comparaison des classifications[modifier | modifier le code]
Les quatre types d'architectures sont illustrés ci-dessous.
-
 SISD
SISD -
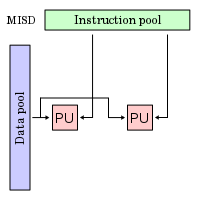 MISD
MISD -
 SIMD
SIMD -
 MIMD
MIMD




Légende :
- PU : unité de calcul (d'un processeur unicœur ou multicœur)
- Instruction Pool : flux d'instructions
- Data Pool : flux de données
Références[modifier | modifier le code]
- Flynn, M., Some Computer Organizations and Their Effectiveness, IEEE Trans. Comput., Vol. C-21, p. 948, 1972.
- Duncan, Ralph, A Survey of Parallel Computer Architectures, IEEE Computer. February 1990, p. 5-16.