
Anaphraseus

| Développé par | Oleg Tsygani, Dmitri Gabinski et Sergei Medvedev |
|---|---|
| Dernière version | Anaphraseus 2.01 bêta |
| Dépôt | sourceforge.net/p/anaphraseus/code/HEAD/tree |
| Environnement | Multiplate-forme |
| Langues | anglais |
| Type | TAO |
| Licence | GPL |
| Site web | anaphraseus.sourceforge.net |
Anaphraseus est un logiciel de traduction assistée par ordinateur (TAO) sous la forme d'un greffon du logiciel de traitement de texte libre OpenOffice Writer. Publié sous licence GPL, il est largement inspiré du logiciel de TAO Wordfast (lequel est un greffon propriétaire de Microsoft Word) et est actuellement développé par un groupe de traducteurs et programmeurs indépendants depuis .
Fonctionnement du logiciel
L'utilisateur ouvre le document à traduire dans OpenOffice Writer et sélectionne ou crée la mémoire de traduction (TM) qu'il souhaite employer. Le format de TM reconnu par le logiciel est celui de Wordfast. Il est également possible d'importer une TM au format standardisé TMX mais le temps de conversion est assez long (on préférera éventuellement avoir recours au logiciel de conversion Okapi Olifant). Anaphraseus offre également la possibilité d'utiliser un ou plusieurs glossaires (listes de mots, recueil terminologique).
La traduction s'effectue de manière linéaire, d'un segment (le plus souvent une phrase) à l'autre : à l'ouverture d'un nouveau segment, le logiciel soumet à l'utilisateur une proposition contenue dans la mémoire de traduction ayant le degré de similarité le plus élevé avec ce segment. L'utilisateur peut accepter cette suggestion, la rejeter ou la modifier. Parallèlement, le logiciel recherche automatiquement les termes présents à l'intérieur du segment et qui sont contenus dans le/les glossaire(s). Une fois la traduction du segment effectuée (passage au segment suivant par exemple), le texte saisi par l'utilisateur est automatiquement enregistré dans la TM et le segment source du texte original est mis en arrière-plan.
Une fois qu'il a terminé de traduire le document, l'utilisateur dispose d'un fichier bilingue : les segments originaux en arrière-plan et les segments traduits (comme après une utilisation de Wordfast ou de Trados Translator's Workbench). Il lui reste à effectuer un « nettoyage » en cliquant sur le menu correspondant. La mémoire de traduction qu'il vient d'« enrichir » en segments nouveaux peut bien entendu être réemployée ultérieurement.
Aperçu des fonctionnalités
Fonctionnalités déjà implantées
- Mémoire de traduction
- Correspondances totales et approximatives (Exact & fuzzy matches)
- Glossaires
Fonctionnalités prévues
- Recherche dans la mémoire de traduction (concordance)
- Analyse du document source/cible
- Fusion de mémoires de traduction
Captures d'écran
-
 Fenêtre de configuration de la mémoire de traduction
Fenêtre de configuration de la mémoire de traduction -
 Fenêtre de gestion des attributs de la mémoire de traduction
Fenêtre de gestion des attributs de la mémoire de traduction -
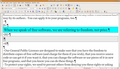 Espace de travail dans OpenOffice.org Writer
Espace de travail dans OpenOffice.org Writer


