
Discussion Wikipédia:Wikiconcours/septembre 2010/Équipes/Équipe 26
Idées d'articles[modifier le code]
à créer[modifier le code]
- Scale-invariant feature transform
- Speeded Up Robust Features
- Détection d'objet (ou reconnaissance d'objet ?)
- détection de visage
- détection de personne (en particulier les piétons!)
- caractéristique
- Image intégrale
- caractéristique pseudo-Haar (ou quasi ?)
- Histogram of oriented gradients
- Local binary patterns
- David G. Lowe
- Différence de Gaussiennes (en)
- Détection de points d'intérêts
- fenêtre glissante]
- sac de mots (bag of word) et plus particulièrement sac de mots visuels. ou bien sac de caractéristiques (bag of features)
- ...
à améliorer[modifier le code]
- Méthode de Viola et Jones
- Histogramme (imagerie numérique)
- Adaboost
- boosting
- Vision par ordinateur
- ...
Contributions effectives[modifier le code]
les créations d'articles connexes, d'images, catégories, etc.. sont à lister sur la page dédiée:
Discussion Wikipédia:Wikiconcours/septembre 2010/Équipes/Équipe 26/contributions
Détection, localisation, reconnaissance[modifier le code]
Selon la terminologie (PascalVOC en particulier) on peut distinguer la détection, de la localisation et de la reconnaissance. En résumé, disons:
- détection: présence d'une instance de l'objet (« une voiture ») dans l'image
- reconnaissance: identification d'une instance particulière (« la voiture de Michael Schumacher »)
- localisation: situation précise de l'instance (détectée ou reconnue) dans l'image (cadre englobant ou segmentation de la zone)
Pour des entités visuelles localisée (objet, visage, personne...), la détection et la localisation se confondent souvent. C'est différent pour des entités plus « abstraites » telles que indoor.outdoor, day/night, landscape/cityscape, etc... Dans ce dernier cas, la localisation n'a pas toujours de sens puisque le concept est présent sur toute l'image.
Si cela fait consensus, cette mise au point pourra faire l'objet d'une section au début de Détection d'objet. Et les deux articles Détection d'objet et reconnaissance d'objet ont donc lieu d'être. Pour les visages par exemple, la détection se fait avec Viola & Jones et la reco avec des (hum...) eigenfaces (comment dit-on en français???).
Mais dans un premier temps il est peut être plus sage de se concentrer sur les techniques de détection plutôt que de reconnaissance. Pour la localisation, il faudra (entre autre) creuser la segmentation d'image...
- Merci pour ta clarification. Rien n'empêche de faire une ébauche minimaliste sur ce qu'est la reconnaissance, sans entrer dans le technique. On risque par contre d'être confronté à des problèmes de traductions de certains termes... traduire ? ou pas, et avec quel terme ? casse-tête. Sylenius (d) 3 septembre 2010 à 22:05 (CEST)
- pour le moment, j'ai mis dans le même article détection et reconnaissance d'objets. L'idée est de présenter la reconnaissance comme s'appliquant aux instances particulière d'un objet (d'où les méthodes d'appariement de caractéristiques locales autour de points d'intérêts) et la détection comme concernant les classes (méthodes de classif supervisées sur diverses caractéristiques). Il est vrai que dans les cas des visages, c'est un peu particulier... Xiawi (d) 15 septembre 2010 à 23:00 (CEST)
Début de traduction de l'article WP:en SIFT[modifier le code]
Organisation[modifier le code]
Bonsoir à vous deux. J’ai commencé, en sous-page dans mon espace utilisateur, la traduction à partir de WP:en de l’article sur SIFT. C’est ici : Utilisateur:Indif/Scale-invariant feature transform. Amitiés. --Indif (d - c) 16 septembre 2010 à 22:37 (CEST)
- C'est un article important, mais je trouve dommage de le faire en sous-page utilisateur. Il me semblerait plus profitable de commencer une « ébauche » en y mettant l'essentiel puis de travailler « dynamiquement » sur l'article; d'autant qu'en lisant le début de ton article, j'aurais bien fait des corrections (typo...) et surtout wikifictions vers des articles récemment crées par Sylenius ou moi-même. Bref, je t'incite à commencer l'article SIFT « en vrai » ! Xiawi (d) 18 septembre 2010 à 13:24 (CEST)
- J’ai bleui le lien SIFT. Tu ne penses pas qu’une traduction de l’article en: soit plus profitable, quitte à l’enrichir de nos apports (PCA-SIFT, SIFT de dim 64, [C/RGB/HSV/Hue-/…]-SIFT…) ? --Indif (d - c) 18 septembre 2010 à 15:20 (CEST)
- Je pense que Xiawi voulait plutôt dire qu'il préférait que le travail soit collectif sur cet article et donc le mettre directement dans l'espace encyclopédique, bref travailler « en public » (j'y suis aussi favorable). Sylenius (d) 18 septembre 2010 à 16:33 (CEST)
- Ce point ne me pose aucun problème, et la page est déjà dans l’espace encyclopédique. La question en suspens est : on traduit et on enrichit ou on part de zéro ? Quel est votre avis à vous deux ? --Indif (d - c) 18 septembre 2010 à 16:49 (CEST)
- plutôt pour la traduction, l'article anglais est bien étoffé et pas trop mal. Il faudra revoir le sourçage, mais ça me parait déjà une bonne base. Repartir de zéro, c'est un gros boulot... Sylenius (d) 18 septembre 2010 à 17:43 (CEST)
- Ouf, je me suis fait des sueurs
 . Juste une précision alors : il ne faut pas trop faire attention, dans l’état actuel de l’article, aux fautes « légères » : orthographe ou typographie. Sitôt terminée la phase de traduction, je procéderai à une reformulation générale du texte. À ce moment-là, je traquerai les fautes [ortho/typo]graphiques. Par contre, les wikiliens sont les bienvenus. Il y a aussi les termes techniques, que j’ai plutôt l’habitude de manipuler en anglais. Si vous connaissez le bon équivalent français, n’hésitez pas ! Et si vous avez des relectures à faire, n’hésitez pas non plus (exemples : Bentley 4½ Litre, Bentley 6½ Litre ou Fiat 804). --Indif (d - c) 18 septembre 2010 à 20:10 (CEST)
. Juste une précision alors : il ne faut pas trop faire attention, dans l’état actuel de l’article, aux fautes « légères » : orthographe ou typographie. Sitôt terminée la phase de traduction, je procéderai à une reformulation générale du texte. À ce moment-là, je traquerai les fautes [ortho/typo]graphiques. Par contre, les wikiliens sont les bienvenus. Il y a aussi les termes techniques, que j’ai plutôt l’habitude de manipuler en anglais. Si vous connaissez le bon équivalent français, n’hésitez pas ! Et si vous avez des relectures à faire, n’hésitez pas non plus (exemples : Bentley 4½ Litre, Bentley 6½ Litre ou Fiat 804). --Indif (d - c) 18 septembre 2010 à 20:10 (CEST)
- Il faut par contre faire attention à l'articulation avec Détection de points d'intérêt. Il faut être bien spécifique à SIFT et ne pas trop donner dans le général. Certains paragraphes sur les comparaisons de méthodes, comme celui-ci: Competing methods for scale invariant object recognition under clutter / partial occlusion, je le verrais bien dans un article plus général. Mais je n'ai pas vraiment réfléchi à la question, on verra après la traduction je dirais
 . Sylenius (d) 18 septembre 2010 à 20:30 (CEST)
. Sylenius (d) 18 septembre 2010 à 20:30 (CEST)
- Bonjour, à l'invitation de Sylenius je serais très heureux de rejoindre votre équipe et de contribuer à la traduction de cet article, si vous le souhaitez. Je débute sur WP aussi je ne sais pas trop comment se passe l'inscription. Par contre je connais bien SIFT... Si vous avez besoin de renfort pouvez vous m'indiquer comment se répartir le travail pour être sûr que personne ne se mord sur les pieds ? Cdt, --Kleliboux (d) 20 septembre 2010 à 20:27 (CEST)
- Au contraire, c’est avec grand plaisir. Je te laisse te rajouter dans la liste des membres de l’équipe. Si cela te convient, on peut travailler sur l’article SIFT en prenant en charge chacun un paragraphe à la suite de l’autre. Il suffit de faire précéder la section que tu veux prendre en charge du bandeau {{en cours}}, et vogue la galère. Une fois terminée la première passe de traduction, on se relira et corrigera l’un l’autre ? Et si tu as des questions, n’hésite pas. Bienvenu donc ! --Indif (d - c) 20 septembre 2010 à 20:55 (CEST)
- +1 bienvenu à bord ! Sylenius (d) 20 septembre 2010 à 21:49 (CEST)
- idem, welcome! J'en profite pour faire une remarque sur SIFT: je trouve que l'article anglais est un peu confu dans la partie "Détection de caractéristiques invariantes aux modifications d’échelle" car il ne fait pas bien la distinction entre "détection des points d'intérêts/clé" puis "calcul d'un vecteur caractéristique". Ce dernier point, n'est explicitement signalé que dans les détails de l'algorithme (section "Descripteur de point clé"). Or c'est à mon sens un aspect important de SIFT, la détection étant après tout pour une grande part des DoG multi-échelle (et des sélection intelligentes" des points les plus robustes). Bref, il me semble que la partie introductive "étapes clé" devrait détailler ces étapes:
- détection de points (DoG, etc...)
- sélection des points robustes (cf. section "Localisation de points clés")
- calcul d'un descripteur (histogramme de gradient sur un grille 4x4)
- Puis enchaîner seulement sur la partie "matching et mise en correspondance des points"
- Cela permet de mettre explicitement en valeur les liens avec Détection de points d'intérêt et extraction de caractéristiques visuelles. Qu'en pensez-vous? Xiawi (d) 20 septembre 2010 à 23:56 (CEST)
- Le plan de l'article anglais n'est peut-être pas bien présenté. Il y a quatre points : la méthodologie SIFT originale de Lowe pour la mise en correspondance d'objets, le descripteur en lui-même (détection et extraction), les variantes proposées (RIFT, SURF, etc) et les applications. Sauf erreur, Lowe a voulu publier une méthodologie complète de mise en correspondance d'objets dans les images mais c'est la sous-partie concernant le calcul du descripteur qui a eu le plus de retentissement, au point qu'on parle de SIFT aujourd'hui comme d'un simple descripteur. Déjà, faire un paragraphe dans l'introduction en expliquant le plan de l'article me semble une bonne idée. Ensuite, peut-être que ce que tu proposes peut être résolu en intervertissant l'ordre des deux premières sections, car c'est finalement la partie détection/extraction qui est la plus intéressante dans SIFT. Qu'en penses-tu ? --Kleliboux (d) 23 septembre 2010 à 10:41 (CEST)
- +1 pour l'explication du plan au début de l'article, avec les étapes claires données par Xiawi, et surtout, faire un résumé introductif plus conséquent, donnant les grandes lignes de l'article, et qui soit accessible. Normalement, le résumé de l'article doit être compréhensible par quasiment tous les lecteurs. Ce n'est pas évident pour un article technique comme celui-ci, donc il faut vraiment le travailler (+ c'est le point d'entrée de l'article, donc important) Sylenius (d) 24 septembre 2010 à 14:01 (CEST)
- Le plan de l'article anglais n'est peut-être pas bien présenté. Il y a quatre points : la méthodologie SIFT originale de Lowe pour la mise en correspondance d'objets, le descripteur en lui-même (détection et extraction), les variantes proposées (RIFT, SURF, etc) et les applications. Sauf erreur, Lowe a voulu publier une méthodologie complète de mise en correspondance d'objets dans les images mais c'est la sous-partie concernant le calcul du descripteur qui a eu le plus de retentissement, au point qu'on parle de SIFT aujourd'hui comme d'un simple descripteur. Déjà, faire un paragraphe dans l'introduction en expliquant le plan de l'article me semble une bonne idée. Ensuite, peut-être que ce que tu proposes peut être résolu en intervertissant l'ordre des deux premières sections, car c'est finalement la partie détection/extraction qui est la plus intéressante dans SIFT. Qu'en penses-tu ? --Kleliboux (d) 23 septembre 2010 à 10:41 (CEST)
- idem, welcome! J'en profite pour faire une remarque sur SIFT: je trouve que l'article anglais est un peu confu dans la partie "Détection de caractéristiques invariantes aux modifications d’échelle" car il ne fait pas bien la distinction entre "détection des points d'intérêts/clé" puis "calcul d'un vecteur caractéristique". Ce dernier point, n'est explicitement signalé que dans les détails de l'algorithme (section "Descripteur de point clé"). Or c'est à mon sens un aspect important de SIFT, la détection étant après tout pour une grande part des DoG multi-échelle (et des sélection intelligentes" des points les plus robustes). Bref, il me semble que la partie introductive "étapes clé" devrait détailler ces étapes:
- +1 bienvenu à bord ! Sylenius (d) 20 septembre 2010 à 21:49 (CEST)
- Au contraire, c’est avec grand plaisir. Je te laisse te rajouter dans la liste des membres de l’équipe. Si cela te convient, on peut travailler sur l’article SIFT en prenant en charge chacun un paragraphe à la suite de l’autre. Il suffit de faire précéder la section que tu veux prendre en charge du bandeau {{en cours}}, et vogue la galère. Une fois terminée la première passe de traduction, on se relira et corrigera l’un l’autre ? Et si tu as des questions, n’hésite pas. Bienvenu donc ! --Indif (d - c) 20 septembre 2010 à 20:55 (CEST)
- Bonjour, à l'invitation de Sylenius je serais très heureux de rejoindre votre équipe et de contribuer à la traduction de cet article, si vous le souhaitez. Je débute sur WP aussi je ne sais pas trop comment se passe l'inscription. Par contre je connais bien SIFT... Si vous avez besoin de renfort pouvez vous m'indiquer comment se répartir le travail pour être sûr que personne ne se mord sur les pieds ? Cdt, --Kleliboux (d) 20 septembre 2010 à 20:27 (CEST)
- Il faut par contre faire attention à l'articulation avec Détection de points d'intérêt. Il faut être bien spécifique à SIFT et ne pas trop donner dans le général. Certains paragraphes sur les comparaisons de méthodes, comme celui-ci: Competing methods for scale invariant object recognition under clutter / partial occlusion, je le verrais bien dans un article plus général. Mais je n'ai pas vraiment réfléchi à la question, on verra après la traduction je dirais
- Ouf, je me suis fait des sueurs
- plutôt pour la traduction, l'article anglais est bien étoffé et pas trop mal. Il faudra revoir le sourçage, mais ça me parait déjà une bonne base. Repartir de zéro, c'est un gros boulot... Sylenius (d) 18 septembre 2010 à 17:43 (CEST)
- Ce point ne me pose aucun problème, et la page est déjà dans l’espace encyclopédique. La question en suspens est : on traduit et on enrichit ou on part de zéro ? Quel est votre avis à vous deux ? --Indif (d - c) 18 septembre 2010 à 16:49 (CEST)
- Je pense que Xiawi voulait plutôt dire qu'il préférait que le travail soit collectif sur cet article et donc le mettre directement dans l'espace encyclopédique, bref travailler « en public » (j'y suis aussi favorable). Sylenius (d) 18 septembre 2010 à 16:33 (CEST)
- J’ai bleui le lien SIFT. Tu ne penses pas qu’une traduction de l’article en: soit plus profitable, quitte à l’enrichir de nos apports (PCA-SIFT, SIFT de dim 64, [C/RGB/HSV/Hue-/…]-SIFT…) ? --Indif (d - c) 18 septembre 2010 à 15:20 (CEST)
Structure[modifier le code]
J'ouvre un nouveau paragraphe pour réinitialiser les indentations, sur la structure de l'article :
- On a acté semble-t-il le fait de faire un paragraphe dans l'introduction en expliquant le plan de l'article.
- Je ne comprends pas l'intérêt du paragraphe Reconnaissance d’objet au moyen des caractéristiques SIFT, c'est une redite quasi-exacte (enfin résumée) du chapitre Etapes-clés. Je m'apprêtais à le traduire mais finalement je trouve ça franchement inutile...
A mon avis le paragraphe "Utilisations" devrait être un paragraphe où l'on donne les principales utilisations du descripteur SIFT proposées postérieurement à l'article de Lowe de 2004, par d'autres chercheurs. Qu'en pensez-vous ?--Kleliboux (d) 1 octobre 2010 à 16:04 (CEST)
- Il faut effectivement absolument une intro, par exemple pour l'instant il n'est pas dit clairement que l'on cherche à faire de la reconnaissance d'objet. Il faut également une partie historique (ou contexte) où on rappelle les travaux précurseurs de Schmid/Mohr et l'impact qu'ont eu les SIFT par la suite.
- à mon avis il faut garder une partie sur la reconnaissance d'objet dans la partie utilisations, mais sans redétailler tout le processus: dire que c'était le but principal de Lowe, et que cela a été repris par de nombreux autres chercheurs par la suite, avec les papiers en référence. On peut également élargir vers le bag of Sift dans cette partie. Sylenius (d) 1 octobre 2010 à 17:49 (CEST)
- Bon, je me suis permis dans ma dernière livraison sur SIFT de tout casser pour tout reconstruire, tellement je trouvais l'article mal organisé. Dans ce nouveau plan (voyez le sommaire), certains passages sont à reformuler et des transitions sont à écrire. Néanmoins, l'ordre des sections principales me paraît bien plus clair ainsi car il laisse apparaître une intention au lecteur. Je n'ai supprimé aucun contenu. Pensez-vous que cela va dans le bon sens ? On peut naturellement annuler cette livraison si un consensus se forme contre moi... --Kleliboux (d) 6 octobre 2010 à 14:10 (CEST)
- Je ne peux qu'acquiescer, tant la version précédente était complètement destructurée. Par ailleurs, cela nous rapproche de la structure de la Méthode de Viola et Jones, et c'est tant mieux. Et à ce propos, je suis partisan de convenir pour touts les descripteurs/méthodes que l'on pourrait traiter d'une structure uniforme (§ introductif, historique, description technique, avantages/inconvénients, applications, améliorations, variantes, etc.). Qu'en pensez-vous ? --Indif (d - c) 6 octobre 2010 à 14:26 (CEST)
- Idem, c'est mieux, j'avais bien du mal à m'y retrouver avant. Sur une structure commune, pourquoi pas si ça tombe sous les doigts, mais sans être trop strict, donc s'autoriser des paragraphes différents selon les spécificités de chaque article, si nécessaire. Sylenius (d) 6 octobre 2010 à 15:30 (CEST)
- Je ne peux qu'acquiescer, tant la version précédente était complètement destructurée. Par ailleurs, cela nous rapproche de la structure de la Méthode de Viola et Jones, et c'est tant mieux. Et à ce propos, je suis partisan de convenir pour touts les descripteurs/méthodes que l'on pourrait traiter d'une structure uniforme (§ introductif, historique, description technique, avantages/inconvénients, applications, améliorations, variantes, etc.). Qu'en pensez-vous ? --Indif (d - c) 6 octobre 2010 à 14:26 (CEST)
- Bon, je me suis permis dans ma dernière livraison sur SIFT de tout casser pour tout reconstruire, tellement je trouvais l'article mal organisé. Dans ce nouveau plan (voyez le sommaire), certains passages sont à reformuler et des transitions sont à écrire. Néanmoins, l'ordre des sections principales me paraît bien plus clair ainsi car il laisse apparaître une intention au lecteur. Je n'ai supprimé aucun contenu. Pensez-vous que cela va dans le bon sens ? On peut naturellement annuler cette livraison si un consensus se forme contre moi... --Kleliboux (d) 6 octobre 2010 à 14:10 (CEST)
Je me permets d'émettre des réserves quant à la pertinence de la section "Historique", qui demande un travail bibliographique approfondi et qui dans sa forme actuelle, contient deux paragraphes, dont un est la redite de l'introduction et l'autre un transfert de la section suivante où il avait toute sa place. Je ne vois pas bien ce qu'on attend dans cette section. S'il faut faire un historique des méthodes de reconnaissance d'objet ou d'extraction de caractéristiques, il faut mieux l'inclure dans ces articles-là, pas dans SIFT. --Kleliboux (d) 5 novembre 2010 à 17:42 (CET)
- Je comprends tes réserves, mais comment faire autrement ? Le résumé introductif impose des contraintes sur son contenu qui nous empêchent d'y importer le contenu de l'« Historique ». La « genèse » de SIFT (les deux articles de Lowe) doivent être abordée dans le corps de l'article et non dans dans le résumé introductif, mais où ? Idem pour les références, qui doivent être évitées dans le résumé introductif. En fait, le rôle joué par ce § est celui d'une introduction qui ne dit pas son nom... Que faire ? --Indif (d - c) 5 novembre 2010 à 19:07 (CET)
- Dans ce cas, voici une proposition : pas d'historique, et fusion de la section actuelle avec la suivante ("Éléments de la méthode") dans une section appelée pour le moment "Généralités". --Kleliboux (d) 5 novembre 2010 à 23:28 (CET)
- On peut en dire plus sur le contexte: les SIFT ne tombent pas du ciel, on peut mentionner les travaux similaires faits auparavant et ce qui a poussé Lowe à proposer une telle méthode. L'article mentionne à peine la popularité, or c'est pourtant un élément important, peu de méthodes ont eu autant d'applications. De plus, l'application originale de Lowe (la mise en correspondance) a été dépassée par le succès du descripteur et ses utilisations en retrieval par exemple avec le BOF. C'est ce genre d'infos que je voyais dans une partie "historique" (peu importe son nom, généralités me va bien) et qui manquent encore amha dans l'article. Il faut essayer de prendre un peu de hauteur de hauteur et de recul. Le bouquin de szeliski peut aider pour cela, outre citer Lowe à tout bout de champ, il dit explicitement p.257: One of the seminal papers on feature detection, description, and matching is David Lowe’s Distinctive image features from scale-invariant keypoints paper (Lowe 2004). Sylenius (d) 6 novembre 2010 à 08:12 (CET)
- Dont acte... Qui s'en charge ? --Kleliboux (d) 6 novembre 2010 à 11:05 (CET)
- Article 212 du Code civil (français) : les époux contribuent aux charges à proportion de leurs facultés respectives . J'ai récupéré le PDF du draft du bouquin, et il y a aussi le premier article de Lowe qui fait un tour d'horizon de l'existant. --Indif (d - c) 6 novembre 2010 à 11:56 (CET)
- Article 212 du Code civil (français) : les époux contribuent aux charges à proportion de leurs facultés respectives
- Dont acte... Qui s'en charge ? --Kleliboux (d) 6 novembre 2010 à 11:05 (CET)
- On peut en dire plus sur le contexte: les SIFT ne tombent pas du ciel, on peut mentionner les travaux similaires faits auparavant et ce qui a poussé Lowe à proposer une telle méthode. L'article mentionne à peine la popularité, or c'est pourtant un élément important, peu de méthodes ont eu autant d'applications. De plus, l'application originale de Lowe (la mise en correspondance) a été dépassée par le succès du descripteur et ses utilisations en retrieval par exemple avec le BOF. C'est ce genre d'infos que je voyais dans une partie "historique" (peu importe son nom, généralités me va bien) et qui manquent encore amha dans l'article. Il faut essayer de prendre un peu de hauteur de hauteur et de recul. Le bouquin de szeliski peut aider pour cela, outre citer Lowe à tout bout de champ, il dit explicitement p.257: One of the seminal papers on feature detection, description, and matching is David Lowe’s Distinctive image features from scale-invariant keypoints paper (Lowe 2004). Sylenius (d) 6 novembre 2010 à 08:12 (CET)
- Dans ce cas, voici une proposition : pas d'historique, et fusion de la section actuelle avec la suivante ("Éléments de la méthode") dans une section appelée pour le moment "Généralités". --Kleliboux (d) 5 novembre 2010 à 23:28 (CET)
Demande de schémas[modifier le code]
Features de Haar[modifier le code]

Puisque nous avons un wikigraphiste parmi nous, autant en profiter ![]() . Indif, est-ce que tu pourrais créer une image sur le modèle de celle-ci: Fichier:Prm VJ fig1 featureTypesWithAlpha.png, mais avec tous les types de formes définies dans cet article, p.2, figure 2, les figures des lignes 1, 2, 3 , pas la 4. N'hésite pas à dire si ça te barbe de le faire, hein, pas de soucis. C'est juste que si j'essaye de faire ça par moi-même, ça va me prendre 3 jours et être très moche
. Indif, est-ce que tu pourrais créer une image sur le modèle de celle-ci: Fichier:Prm VJ fig1 featureTypesWithAlpha.png, mais avec tous les types de formes définies dans cet article, p.2, figure 2, les figures des lignes 1, 2, 3 , pas la 4. N'hésite pas à dire si ça te barbe de le faire, hein, pas de soucis. C'est juste que si j'essaye de faire ça par moi-même, ça va me prendre 3 jours et être très moche ![]() . Sylenius (d) 19 septembre 2010 à 17:04 (CEST)
. Sylenius (d) 19 septembre 2010 à 17:04 (CEST)
- OK. Question, par contre : le positionnement des lettres A, B, C et D a-t-il son importance ? Représentent-elles des quantités mathématiques (à mettre donc en italique mathématique) ? --Indif (d - c) 19 septembre 2010 à 17:32 (CEST)
- Non, et tu peux même utiliser des chiffres, de 1 à 14 normalement, c'est plus pratique que des lettres. Sylenius (d) 19 septembre 2010 à 17:48 (CEST)
- OK. Pour la traduction des titres, en plus de caractéristiques de bord, caractéristiques de ligne, comment se traduit center-surround features ? --Indif (d - c) 19 septembre 2010 à 18:13 (CEST)
- Il me faut aussi le titre sous lequel j’importerai l’illustration sous Commons. --Indif (d - c) 19 septembre 2010 à 18:15 (CEST)
- caractéristique centre-pourtour ? Pour le titre, je te propose Haar_features_Lienhart. Merci. Sylenius (d) 19 septembre 2010 à 18:40 (CEST)
- Ton avis ? --Indif (d - c) 19 septembre 2010 à 19:56 (CEST)
- super !! merci beaucoup ! Sylenius (d) 19 septembre 2010 à 21:40 (CEST)
- J’ai rajouté de la marge tout autour de l’illustration, qui collait trop les bords. --Indif (d - c) 19 septembre 2010 à 22:09 (CEST)
- super !! merci beaucoup ! Sylenius (d) 19 septembre 2010 à 21:40 (CEST)
- Ton avis ? --Indif (d - c) 19 septembre 2010 à 19:56 (CEST)
- caractéristique centre-pourtour ? Pour le titre, je te propose Haar_features_Lienhart. Merci. Sylenius (d) 19 septembre 2010 à 18:40 (CEST)
- Non, et tu peux même utiliser des chiffres, de 1 à 14 normalement, c'est plus pratique que des lettres. Sylenius (d) 19 septembre 2010 à 17:48 (CEST)
SIFT et Pyramides[modifier le code]
- Kleliboux, tu es entrain de faire des miracles sur l'article SIFT Merci
 . Je dois reconnaître que j'ai quelque peu surestimé mes connaissances et mes capacités quand je me suis attaqué à cet article. Pour être quelque peu utile, en attendant que l'article soit prêt à la relecture, aurais-tu besoin de schémas es DoG, de gradients d'images ou autre ? --Indif (d - c) 15 octobre 2010 à 17:53 (CEST)
. Je dois reconnaître que j'ai quelque peu surestimé mes connaissances et mes capacités quand je me suis attaqué à cet article. Pour être quelque peu utile, en attendant que l'article soit prêt à la relecture, aurais-tu besoin de schémas es DoG, de gradients d'images ou autre ? --Indif (d - c) 15 octobre 2010 à 17:53 (CEST)
- Merci, voici quelques idées qui me viennent à l'esprit :
- pour l'illustration générale, il faudrait une photo et ses points-clés SIFT figurés comme des cercles de différents rayons (rayon du cercle en pixels = 3x le facteur d'échelle du point-clé), mais pour cela il te faut à la fois une photo libre de droits, bien choisie, et un soft de détection de points-clés SIFT (j'avais utilisé SIFT++ dans le passé, il marche bien, mais il faut savoir un peu coder, compiler, etc)
- une ou plusieurs illustrations de la notion de pyramide de gradients (elle pourrait resservir pour l'article Pyramide). J'en ai des exemples bricolés que je peux t'envoyer par mail mais que je ne peux pas utiliser car il se fondent sur des images non libres de droits (dont j'ai perdu l'auteur en plus).
- pour le calcul du descripteur, il faudrait peut-être un schéma qui montre comment on construit l'histogramme. Là je n'ai pas trop réfléchi à son contenu ; je trouve que les schémas de Lowe ne sont pas clairs - je me suis longtemps gratté la tête dessus, il faudrait peut-être trouver quelque chose de plus pédagogique.
- Vaste chantier...--Kleliboux (d) 19 octobre 2010 à 10:30 (CEST)
- Bonjour Kleliboux,
- Des images utilisables, ce n'est pas ce qui manque sur Commons
 . Et pour le soft de détection de points-clés, je pense que celui de Lowe est à préférer ; il est de plus librement utilisable pour un usage non commercial, ce qui est bien le cas ici. Par contre, il faudrait un image ne générant pas trop de points, pour que le résultat final reste quand même lisible et pédagogique.
. Et pour le soft de détection de points-clés, je pense que celui de Lowe est à préférer ; il est de plus librement utilisable pour un usage non commercial, ce qui est bien le cas ici. Par contre, il faudrait un image ne générant pas trop de points, pour que le résultat final reste quand même lisible et pédagogique. - Idem, il suffit de sélectionner une image sur Commons (de préférence la même que ci-dessus), et on n'a plus qu'à bricoler ce qu'il nous faut.
- Comment souvent il suffit juste d'un point de départ, je vais essayer de faire des propositions, qu'il suffira ensuite de corriger en fonction des remarques de tous, comme ce fut le cas pour la cascade de Viola et Jones.
- Des images utilisables, ce n'est pas ce qui manque sur Commons
- Et comme les Dupont, je dirai même très vaste chantier . --Indif (d - c) 19 octobre 2010 à 12:14 (CEST)
- Que penses-tu de ces deux images, dans lesquels on ferait correspondre les deux iMac G5 ? --Indif (d - c) 19 octobre 2010 à 20:25 (CEST)
- Plutôt la première, à cause de l'abondance d'objets. L'écran du Mac est probablement cadré trop serré pour apparaître comme une zone d'intérêt, ceci dit... A toi de voir si une fois passé le détecteur, ça te semble suffisamment illustratif. --Kleliboux (d) 21 octobre 2010 à 11:15 (CEST)
- En fait, je pensais reproduire la mise en correspondance de la page 3 de cet article. --Indif (d - c) 21 octobre 2010 à 19:03 (CEST)
- Je n'avais pas compris excuse-moi. C'est une excellente idée. Par contre, comme tu vois sur ton article, SIFT va mettre les détails de la tour de Pise en correspondance, et non la tour de Pise elle-même, or l'écran du Mac me semble un peu trop dépourvu de détails puisque c'est un rectangle noir...--Kleliboux (d) 22 octobre 2010 à 12:29 (CEST)
- En fait, je pensais reproduire la mise en correspondance de la page 3 de cet article. --Indif (d - c) 21 octobre 2010 à 19:03 (CEST)
- Plutôt la première, à cause de l'abondance d'objets. L'écran du Mac est probablement cadré trop serré pour apparaître comme une zone d'intérêt, ceci dit... A toi de voir si une fois passé le détecteur, ça te semble suffisamment illustratif. --Kleliboux (d) 21 octobre 2010 à 11:15 (CEST)
- Que penses-tu de ces deux images, dans lesquels on ferait correspondre les deux iMac G5 ? --Indif (d - c) 19 octobre 2010 à 20:25 (CEST)
- Bonjour Kleliboux,
- J'espérais, j'espérais que les deux iMac génèrent assez de points (mais pas trop non plus) pour donner une illustration de correspondance, sans pour autant être inondé de centaines ou milliers de lignes de correspondance. Il n'y a même pas le moindre point de correspondance. Je pars en quête d'images. Si l'un de vous a quelque chose à me proposer, une idée, qu'il n'hésite pas... --Indif (d - c) 22 octobre 2010 à 16:49 (CEST)
-
 Proposition 1
Proposition 1 -
 Proposition 2
Proposition 2



- Je vous propose le montage ci-contre pour illustrer les échelles et octaves. --Indif (d - c) 20 octobre 2010 à 13:05 (CEST)
- Merci pour cette proposition, ne serait-il pas possible d'avoir des imagettes carrées et de caser une ou deux octaves de plus (les unes sous les autres) ? Je pense que ce serait bien d'avoir la valeur du sigma sous chacune des imagettes, aussi... Sur le titre : non pas "SIFT scales and octaves" mais "Pyramid of gradients" (SIFT travaille sur les DoG - différences of gradients - il y a donc une opération supplémentaire à faire après avoir calculé les images de ta pyramide) --Kleliboux (d) 21 octobre 2010 à 11:15 (CEST)
- Et là ? --Indif (d - c) 21 octobre 2010 à 18:40 (CEST)
- Bien mieux. Par contre le sigma correspond à un paramètre de filtre gaussien ; donc au sein d'une même octave, les images doivent apparaître de plus en plus floues — mais pas trop non plus : pour respecter la logique d'une pyramide, le rayon du dernier flou doit être égal au double du rayon du premier flou (), de telle sorte qu'il soit plus économique en calculs de diviser l'image par 2 (passer à l'octave suivante) que de continuer à flouter la grande image...--Kleliboux (d) 22 octobre 2010 à 12:29 (CEST)
- Ma compréhension de l'algorithme est que la première image d'une octave est l'exacte moitié de la première image de l'octave précédente, et la « copie conforme » de la dernière image de la même octave précédente. C'est bien qu'est supposée représenter l'illustration, même si cela ne semble pas évident au premier coup d'œil. Est-ce mon choix d'image qui ne convient pas ? Est-ce la conséquence d'avoir réduit la taille du résultat final ?
Est-ce la qualité de l'enregistrement au format JPEG qui égalise trop les images ?Je ne sais pas. Il faudrait peut-être que je change l'image pour une autre sur laquelle les floutages successifs se verront mieux. Je me replonge dedans. --Indif (d - c) 22 octobre 2010 à 16:36 (CEST)- Je ne suis pas sûr de comprendre ce que tu veux dire, mais sache que la première image d'une octave s'obtient à partir de la dernière image de l'octave précédente, juste en divisant les proportions comme tu fais. Et au sein d'une octave chaque image est le floutage de la précédente. Du coup les flous s'accumulent, et la toute dernière image (dernière octave, flou ) doit apparaître vraiment vraiment floue, comme si on était myope...--Kleliboux (d) 22 octobre 2010 à 18:43 (CEST)
- Il est normal que tu ne sois pas sûr de comprendre ce que je veux, moi-même je n'y arrive pas
 . Je vérifie mon code et je reviens à la charge . --Indif (d - c) 22 octobre 2010 à 22:18 (CEST)
. Je vérifie mon code et je reviens à la charge . --Indif (d - c) 22 octobre 2010 à 22:18 (CEST)
- Cette fois-ci, c'est la bonne. Les images étaient placées dans le désordre lors de leur importation dans le fichier final. J'ai dû les vérifier toutes une par une. --Indif (d - c) 23 octobre 2010 à 07:02 (CEST)
- Et pour info, il y a 7 octaves au total, et je n'en ai représentées que 3 (de la 3e à la 5e). Cela prend trop de place de toutes les mettre. --Indif (d - c) 23 octobre 2010 à 09:18 (CEST)
- On s'en rapproche... comment fabriques-tu l'image de l'octave 2, échelle ? --Kleliboux (d) 23 octobre 2010 à 15:33 (CEST)
- Tout simplement en utilisant la SIFT Library de Rob Hess (que j'ai installée sur une machine Linux), à laquelle j'ai ajouté les quelques lignes de code nécessaires à l'enregistrement de la pyramide de gradients et des DoGs
 . --Indif (d - c) 23 octobre 2010 à 18:39 (CEST)
. --Indif (d - c) 23 octobre 2010 à 18:39 (CEST)
- Arf ça doit être correct alors :) J'aimerais bien connaître la valeur exacte des sigmas juste pour ma compréhension personnelle, si tu l'as sous la main, sinon tant pis :) Ton image est bien je trouve. --Kleliboux (d) 23 octobre 2010 à 20:23 (CEST)
- Voici les valeurs que je récupère (octave et intervalle) :
- (0, 0) = 1.6 (valeur de départ)
- (0, 1) à (0, 5) = 1.226, 1.545, 1.947, 2.453, 3.090
- (1, 1) à (1, 5) = idem, et ainsi de suite pour les octaves 2 à 6
- --Indif (d - c) 23 octobre 2010 à 21:29 (CEST)
- Et en plus, je peux m'attaquer au schéma des DoGs ! --Indif (d - c) 23 octobre 2010 à 21:31 (CEST)
- Voici les valeurs que je récupère (octave et intervalle) :
- Arf ça doit être correct alors :) J'aimerais bien connaître la valeur exacte des sigmas juste pour ma compréhension personnelle, si tu l'as sous la main, sinon tant pis :) Ton image est bien je trouve. --Kleliboux (d) 23 octobre 2010 à 20:23 (CEST)
- Tout simplement en utilisant la SIFT Library de Rob Hess (que j'ai installée sur une machine Linux), à laquelle j'ai ajouté les quelques lignes de code nécessaires à l'enregistrement de la pyramide de gradients et des DoGs
- On s'en rapproche... comment fabriques-tu l'image de l'octave 2, échelle ? --Kleliboux (d) 23 octobre 2010 à 15:33 (CEST)
- Il est normal que tu ne sois pas sûr de comprendre ce que je veux, moi-même je n'y arrive pas
- Je ne suis pas sûr de comprendre ce que tu veux dire, mais sache que la première image d'une octave s'obtient à partir de la dernière image de l'octave précédente, juste en divisant les proportions comme tu fais. Et au sein d'une octave chaque image est le floutage de la précédente. Du coup les flous s'accumulent, et la toute dernière image (dernière octave, flou ) doit apparaître vraiment vraiment floue, comme si on était myope...--Kleliboux (d) 22 octobre 2010 à 18:43 (CEST)
- Ma compréhension de l'algorithme est que la première image d'une octave est l'exacte moitié de la première image de l'octave précédente, et la « copie conforme » de la dernière image de la même octave précédente. C'est bien qu'est supposée représenter l'illustration, même si cela ne semble pas évident au premier coup d'œil. Est-ce mon choix d'image qui ne convient pas ? Est-ce la conséquence d'avoir réduit la taille du résultat final ?
- Bien mieux. Par contre le sigma correspond à un paramètre de filtre gaussien ; donc au sein d'une même octave, les images doivent apparaître de plus en plus floues — mais pas trop non plus : pour respecter la logique d'une pyramide, le rayon du dernier flou doit être égal au double du rayon du premier flou (), de telle sorte qu'il soit plus économique en calculs de diviser l'image par 2 (passer à l'octave suivante) que de continuer à flouter la grande image...--Kleliboux (d) 22 octobre 2010 à 12:29 (CEST)
- Et là ? --Indif (d - c) 21 octobre 2010 à 18:40 (CEST)




- C'est au tour des DoGs ! --Indif (d - c) 24 octobre 2010 à 00:31 (CEST)
- Merci bcp pour ces schémas qui me semblent très bien et pour les infos sur les valeurs des sigmas. J'ai été très occupé ces derniers temps, promis je m'y remets à fond dès demain. La mise en correspondance sur Delacroix est très parlante, bravo. Il faudrait peut-être un exemple d'image avec les points-clés et leurs rayons variables pour bien illustrer l'aspect multi-échelle de la méthode (ou le faire directement sur l'illustration de mise en correspondance sur Delacroix mais j'ai peur que ça la surcharge trop). Une erreur qui m'a sauté aux yeux sur le schéma "Exemple de détection d'extrémums..." : ce ne sont pas les différentes octaves qui sont comparées, mais les images précédente et suivante au sein d'une même octave. --Kleliboux (d) 2 novembre 2010 à 17:29 (CET)
- Très content que tu sois de retour J'ai essayé de faire au mieux, et il y a encore à faire sur cet article. Mon idée est de finir mes relectures, te céder la place, pour m'attaquer aux toutes dernières illustrations, aux liens rouges les plus importants, etc. Ah, si on pouvait le présenter au label BA avant la fin du concours... --Indif (d - c) 2 novembre 2010 à 22:34 (CET)
- Très content que tu sois de retour
- Indif, voici quelques remarques sur l'image détection d'extremums - On ne compare pas différentes octaves, donc il faut remplacer « octave n-1 » par , « octave n » par et « octave n+1 » par . Dans l'idéal il faudrait aussi intervertir les agrandissements de sorte que le point central sur la couche du milieu apparaisse comme un extremum, c'est-à-dire comme le point plus noir (ou le plus blanc) de tous. --Kleliboux (d) 7 novembre 2010 à 11:47 (CET)



- OK. Je ferai cela ce soir. --Indif (d - c) 7 novembre 2010 à 13:14 (CET)
 Fait. --Indif (d - c) 7 novembre 2010 à 19:40 (CET)
Fait. --Indif (d - c) 7 novembre 2010 à 19:40 (CET)
- Parfait ! Merci. --Kleliboux (d) 7 novembre 2010 à 20:11 (CET)
- A propos de l'image Fichier:Example_of_SIFT_features.jpg. Ce qui est représenté sur cette image n'est pas clair. Je suppose que la direction représentée en chaque point-clé est la direction principale associée au point ; mais la norme correspond-elle à l'amplitude du gradient ou au rayon (facteur d'échelle) du point clé ? Serait-il possible d'enrichir l'image en faisant figurer les points-clés comme des cercles pour bien montrer qu'il s'agit de zones d'intérêt (le rayon du cercle étant égal à 3 fois le facteur d'échelle du point clé) ? Ou sinon d'enrichir la légende de l'image en précisant ce qui est représenté et ce qui manque ? --Kleliboux (d) 13 novembre 2010 à 14:52 (CET)
- Très très vite, car je dois filer : c'est bien le facteur d'échelle qui est représenté. --Indif (d - c) 13 novembre 2010 à 15:18 (CET)
- Je vais essayer l'ajout des cercles, mais j'ai peur que cela n'encombre plus qu'autre chose l'image, qui en deviendra illisible. --Indif (d - c) 13 novembre 2010 à 16:59 (CET)
Détection de personne[modifier le code]
Pour détection de personne, j'aurais besoin d'une ou plusieurs images de piétons avec boites englobantes, comme dans http://www.merl.com/projects/images/pedestrian.jpg ou http://www.migmasys.com/Pedestrian_Detection.html . Si possible une image qui ferait plutôt vidéo-surveillance, et une autre qui ferait détection dans un véhicule un peu comme dans http://www.youtube.com/watch?v=I4EY9_mOvO8 à 0:45. Sylenius (d) 21 octobre 2010 à 14:42 (CEST)
- Y aurait-il ici sur Flickr des images qui puissent t'intéresser ? Elles sont toutes sous licence CC-BY-SA et donc librement téléchargeables sur Commons. Il faudrait faire la même recherche avec "pedestrian". Idem pour cette recherche Google Images. --Indif (d - c) 21 octobre 2010 à 15:03 (CEST)
- ça c'est pas mal pour de la surveillance: http://www.flickr.com/photos/endymion120/4888970869/ ou ça http://www.flickr.com/photos/ll0zz/2090065554/ et ça http://www.flickr.com/photos/endymion120/4756329463/ .~Merci. Sylenius (d) 21 octobre 2010 à 15:29 (CEST)
- Indif, est ce que tu peux tracer des boites englobantes sur les piétons de chacune de ces 3 images et les importer sur commons ? je l'aurais bien fait mais je ne suis pas sur mon ordi perso pendant un moment, et je n'ai pas mes outils habituels. Merci. Sylenius (d) 29 octobre 2010 à 10:12 (CEST)
- Bonjour Sylenius. J'ai déjà transféré les trois images de flickr à Commons. J'attaque ce midi l'ajout des boîtes. --Indif (d - c) 29 octobre 2010 à 11:39 (CEST)
- Indif, est ce que tu peux tracer des boites englobantes sur les piétons de chacune de ces 3 images et les importer sur commons ? je l'aurais bien fait mais je ne suis pas sur mon ordi perso pendant un moment, et je n'ai pas mes outils habituels. Merci. Sylenius (d) 29 octobre 2010 à 10:12 (CEST)
- ça c'est pas mal pour de la surveillance: http://www.flickr.com/photos/endymion120/4888970869/ ou ça http://www.flickr.com/photos/ll0zz/2090065554/ et ça http://www.flickr.com/photos/endymion120/4756329463/ .~Merci. Sylenius (d) 21 octobre 2010 à 15:29 (CEST)
-
 Image 1
Image 1 -
 Image 2
Image 2 -
 Image 3
Image 3



- ok ! Pour l'image du milieu, pourrais tu supprimer les boites sur les deux personnes assises ? Merci ! Sylenius (d) 29 octobre 2010 à 21:23 (CEST)
- --Indif (d - c) 29 octobre 2010 à 22:08 (CEST)
- Super, merci ! Sylenius (d) 29 octobre 2010 à 22:20 (CEST)
Adoption d'un lexique[modifier le code]
Bonjour à vous deux. Je vous propose de mettre en place une liste des différents termes techniques liés à la vision et leur équivalent français. Peut-être faudrait-il créer une page dédiée à ce lexique ? En attendant, voici une première liste :
- en:object recognition : détection d'objet
- en:robotic mapping : ?
- en:image stitching : assemblage de panorama, assemblage d'image… ?
- en:gesture recognition : détection de mouvement ?
- en:video tracking : tracking
- en:match moving : match moving
- training image : image d’apprentissage
- test image : image de test
- cluster : grappe
- …
--Indif (d - c) 20 septembre 2010 à 11:11 (CEST)
- quelques remarques:
- en:gesture recognition -> détection de gestes, tout simplement.
- en:image stitching : je ne connais pas de traduction répandue, mais assemblage de panorama ne me semble pas correct: le panorama, c'est le résultat
- cluster -> utiliser cluster
- en:video tracking -> suivi d'objet (il faudrait créer un article dédié, Tracking est plutôt HS. Sylenius (d) 20 septembre 2010 à 12:02 (CEST)
- Merci Sylenius. J’ai finalement créé la page de Lexique, pour m’éviter surtout à moi de me perdre dans les termes . Il ne faudra pas hésiter pas à me corriger et à l’enrichir. --Indif (d - c) 20 septembre 2010 à 12:28 (CEST)
Titre et répartition des contenus[modifier le code]
Suite à la discussion avec Kleliboux (d · c · b) sur Discussion:Extraction de caractéristique en vision par ordinateur et à la coexistence des articles Détection de points d'intérêt, Détection de caractéristiques et Extraction de caractéristique en vision par ordinateur, je pense qu'il faut que l'on soit bien d'accord à la fois sur les titres et la répartition du contenu et leur hiérarchie. Pas vraiment réfléchi longtemps, mais rapidement, il me semble que l'on devrait avoir Extraction de caractéristique en vision par ordinateur comme l'article le plus général, qui utilise un {{article détaillé}} vers Détection de caractéristiques, qui lui même renvoie en article détaillé à Détection de points d'intérêt. Sur les titres, la proposition de Kleliboux d'utiliser Détection de caractéristiques visuelles et extraction de caractéristiques visuelles me va, pas d'objection en tout cas. Des avis ? Sylenius (d) 20 septembre 2010 à 21:48 (CEST)
- J'avoue que l'article Détection de points d'intérêt avait pour but de s'inspirer dudit article anglais en::feature extraction et de l'article externe [1]. Il était donc mal nommé et aurait dû s'appeler Détection de zone d'intérêt. Par contre, j'hésiterais à laisser une traduction trop "litterale" telle Détection de caractéristiques car il me semble que ce sont plutôt des "zones d'intérêts" qui sont recherchées et que c'est en ces zones (coins, bords, blobs/régions, etc...) que sont calculés les features. Ce sont finalement ces derniers (via éventuellement une agrégation par Bag-of-features) qui servent des description de l'image dans un espace vectoriel de dimension finie ou qui sont mis en correspondance (KNN, Kd-tre, RANSAC, etc...). Il est vrai que le feature utilisé peut être simplement la luminosité locale (patch) autour du point d'intérêt (surtout pour la mise en correspondance, voir dans ce cas une "simple" mise en correspondance géométrique des points localisés), mais je vois néanmoins comme un feature particulier. Je crois que cela dépend aussi si on s'intéresse à la détection de classes d'objets (généricité) ou d'instances particulière (match exact). Qu'en pensez-vous? Xiawi (d) 21 septembre 2010 à 00:26 (CEST)
- Tu as parfaitement raison sur la traduction trop littérale et le fait que "caractéristique (visuelle)" renvoie davantage au vecteur d'informations local qu'à la zone elle-même sur laquelle il est calculé. Maintenant que j'y pense, le terme couramment utilisé est "descripteur" (ou "vecteur descripteur"). Voici une proposition synthétique:
- Renommer Détection de caractéristiques en Détection de zones d'intérêt
- Détection de points d'intérêt peut se contenter d'être une redirection vers le paragraphe concerné dans Détection de zones d'intérêt - le contenu actuel peut être fusionné audit paragraphe. A moins que Xiawi n'avait l'intention d'en faire un article très détaillé.
- Renommer Extraction de caractéristique en vision par ordinateur en utilisant le terme de "descripteur" au lieu de "caractéristique" (Extraction de descripteur ? Calcul de descripteurs locaux en vision par ordinateur ?)
- --Kleliboux (d) 21 septembre 2010 à 02:52 (CEST)
- Attention quand même, il faut garder en tête que Extraction de caractéristique en vision par ordinateur (ou quelque soit son nom) doit être suffisamment générique pour englober tous les cas, et pas que les descripteurs locaux. Il est clair que nous cherchons à mettre sur une seule page quelque chose qui en français a plusieurs noms, ou même pour lequel on utilise souvent le terme anglais feature, bien plus fourre-tout. Descripteur n'est pas vraiment mieux que caractéristique, ça dépend du contexte. On parle de descripteur SIFT, mais quand on fait de la classification multimédia avec de nombreux attributs hétérogènes, on parle plus volontiers de caractéristique (par exemple la longueur d'un plan en vidéo). Il ne faut pas que le titre soit trop restrictif, quitte à avoir un titre assez peu explicite et à faire un article assez général qui renvoie à plusieurs autres plus précis avec l'utilisation du modèle {{article détaillé}}. Je suis plutôt pour un titre assez neutre et simple, du genre Extraction de caractéristique. Sylenius (d) 21 septembre 2010 à 09:28 (CEST) je l'avais dit que ça allait être compliqué
- D'accord pour le renommage de Détection de caractéristiques en Détection de zones d'intérêt et la redirection de Détection de points d'intérêt vers le paragraphe concerné dans Détection de zones d'intérêt.
- Pour la traduction de feature, on a pour le moins « caractéristique », « descripteur » voire « primitive » ou « attribut » (j'ai même déjà vu « trait »!). le mieux est sans doute de faire un paragraphe sur la traduction de feature. Par contre il vaut mieux garder le contexte « vision par ordi », parce que je n'ai pas envie de parler de toute la reconnaissance des formes! Par ex, mes amis du « traitement automatique des langues » font aussi de l'extraction de caractéristiques... A eux!. On peut faire un titre du genre Extraction de caractéristique (vision par ordinateur)? Xiawi (d) 21 septembre 2010 à 13:47 (CEST)
- On retrouve aussi les termes « caractéristiques » et « descripteurs » en chimie, dans le domaine des relations quantitatives structure à activité/propriété, et il arrive souvent, malheureusement, qu’ils soient confondus. Un développement sur ces deux concepts s’impose à mon avis. --Indif (d - c) 21 septembre 2010 à 14:07 (CEST)
- Le TAL, l'audio, etc... tous les gens qui font de la classif finalement. Est-ce que l'on fait une ébauche du style Extraction de caractéristique par exemple basé sur en:Features (pattern recognition) en mettant juste une définition simple et générique, et ensuite des renvois vers des articles détaillés Extraction de caractéristique (vision par ordinateur), Extraction de caractéristique (audio), Extraction de caractéristique (TAL), etc... ? (la pour le coup les parenthèses sont justifiées car homonymie) Sylenius (d) 21 septembre 2010 à 14:53 (CEST)
- Tout à fait d’accord avec toi. --Indif (d - c) 22 septembre 2010 à 11:21 (CEST)
- Puisque cela semble faire consensus, j'ai commencé une telle structure. Pour le moment extraction de caractéristique est redirigé vers extraction de caractéristique (homonymie). Ce dernier traitant uniquement de reco de formes, j'en ai fait autant pour extraction de caractéristique (reconnaissance des formes). Xiawi (d) 22 septembre 2010 à 23:57 (CEST)
- Cela me convient ; est-ce qu'il y a aussi consensus sur l'histoire du renommage en Détection de zones d'intérêt ?--Kleliboux (d) 23 septembre 2010 à 10:45 (CEST)
- il me semble, oui. Sylenius (d) 23 septembre 2010 à 10:56 (CEST)
- Oui également. zone peut être mis au singulier (je sais qu'il est rare d'en détecter une seule, mais vu qu'on a commencé à mettre au singulier détection d'objet, Extraction de caractéristique, reconnaissance de visage, etc... cela peut être plus cohérent. A toi de voir. Xiawi (d) 23 septembre 2010 à 12:12 (CEST)
- OK je l'ai fait, j'ai finalement conservé le pluriel et rajouté un lien vers l'extraction dans la derniere section. J'ai gardé le pluriel qui avait été adopté pour Détection de points d'intérêt. Le singulier se justifie mieux pour les caractéristiques car lorsqu'elles sont globales, elles sont une, alors que les zones d'intérêt sont toujours locales :) --Kleliboux (d) 23 septembre 2010 à 16:24 (CEST)
- Oui également. zone peut être mis au singulier (je sais qu'il est rare d'en détecter une seule, mais vu qu'on a commencé à mettre au singulier détection d'objet, Extraction de caractéristique, reconnaissance de visage, etc... cela peut être plus cohérent. A toi de voir. Xiawi (d) 23 septembre 2010 à 12:12 (CEST)
- il me semble, oui. Sylenius (d) 23 septembre 2010 à 10:56 (CEST)
- Cela me convient ; est-ce qu'il y a aussi consensus sur l'histoire du renommage en Détection de zones d'intérêt ?--Kleliboux (d) 23 septembre 2010 à 10:45 (CEST)
- Puisque cela semble faire consensus, j'ai commencé une telle structure. Pour le moment extraction de caractéristique est redirigé vers extraction de caractéristique (homonymie). Ce dernier traitant uniquement de reco de formes, j'en ai fait autant pour extraction de caractéristique (reconnaissance des formes). Xiawi (d) 22 septembre 2010 à 23:57 (CEST)
- Tout à fait d’accord avec toi. --Indif (d - c) 22 septembre 2010 à 11:21 (CEST)
- Le TAL, l'audio, etc... tous les gens qui font de la classif finalement. Est-ce que l'on fait une ébauche du style Extraction de caractéristique par exemple basé sur en:Features (pattern recognition) en mettant juste une définition simple et générique, et ensuite des renvois vers des articles détaillés Extraction de caractéristique (vision par ordinateur), Extraction de caractéristique (audio), Extraction de caractéristique (TAL), etc... ? (la pour le coup les parenthèses sont justifiées car homonymie) Sylenius (d) 21 septembre 2010 à 14:53 (CEST)
- On retrouve aussi les termes « caractéristiques » et « descripteurs » en chimie, dans le domaine des relations quantitatives structure à activité/propriété, et il arrive souvent, malheureusement, qu’ils soient confondus. Un développement sur ces deux concepts s’impose à mon avis. --Indif (d - c) 21 septembre 2010 à 14:07 (CEST)
- Attention quand même, il faut garder en tête que Extraction de caractéristique en vision par ordinateur (ou quelque soit son nom) doit être suffisamment générique pour englober tous les cas, et pas que les descripteurs locaux. Il est clair que nous cherchons à mettre sur une seule page quelque chose qui en français a plusieurs noms, ou même pour lequel on utilise souvent le terme anglais feature, bien plus fourre-tout. Descripteur n'est pas vraiment mieux que caractéristique, ça dépend du contexte. On parle de descripteur SIFT, mais quand on fait de la classification multimédia avec de nombreux attributs hétérogènes, on parle plus volontiers de caractéristique (par exemple la longueur d'un plan en vidéo). Il ne faut pas que le titre soit trop restrictif, quitte à avoir un titre assez peu explicite et à faire un article assez général qui renvoie à plusieurs autres plus précis avec l'utilisation du modèle {{article détaillé}}. Je suis plutôt pour un titre assez neutre et simple, du genre Extraction de caractéristique. Sylenius (d) 21 septembre 2010 à 09:28 (CEST) je l'avais dit que ça allait être compliqué
- Tu as parfaitement raison sur la traduction trop littérale et le fait que "caractéristique (visuelle)" renvoie davantage au vecteur d'informations local qu'à la zone elle-même sur laquelle il est calculé. Maintenant que j'y pense, le terme couramment utilisé est "descripteur" (ou "vecteur descripteur"). Voici une proposition synthétique:
Expression faciale[modifier le code]
Salut,
Je ne suis pas expert de la vision par ordinateur proprement dite mais j'ai eu l'occasion de m'intéresser à la reconnaissance des expressions faciales (quels sont les systèmes disponibles, les corpus pour l'apprentissage et les catégories retenues, performance, problèmes d'interprétation, etc.) donc si ça cadre avec l'un de vos articles (peut-être un paragraphe quelquepart dans un article plus large), n'hésitez pas à me faire signe.
Cordialement, GL (d) 22 septembre 2010 à 11:35 (CEST)
- salut, merci pour la proposition. On va voir ça quand on attaquera détection de visage, on va certainement créer un article reconnaissance de visage également, dans lequel on peut intégrer la reconnaissance d'expressions. On en est pas encore là pour l'instant . Sylenius (d) 22 septembre 2010 à 12:09 (CEST)
Relectures[modifier le code]
Méthode de Viola et Jones[modifier le code]
A part quelques micro-truc, j'ai fini ce que je voulais faire sur cet article, donc j'aimerais si possible une relecture de votre part sur le fond et la forme. N'hésitez pas à dire ce qui ne vous plait pas. Sylenius (d) 30 septembre 2010 à 14:47 (CEST)
- Moi qui n'avais qu'une vague idée de la méthode, j'ai tout compris. Je trouve l'article vraiment intéressant, surtout que tu as bien détaillé certaines étapes par rapport à l'article anglais. Mes premières remarques ne concernent que la forme:
- Pourquoi les notes 1, 2, 3 ? Je trouve qu'il faudrait mieux les insérer en tant que telles dans le flux du texte, je ne vois pas de justification pour les écrire en tant que notes de bas de page.
- Tu utilises beaucoup l'expression "scanner l'image", il me semble que le terme correct est "parcourir".
- J'aurais traduit le petit exemple de l'article anglais quant aux formules sur les fausses alarmes et les taux de détection, car si les formules sont analogues, l'une a un sens positif, l'autre négatif (le fait d'empiler les étages permet de diminuer les fausses alarmes, mais diminue aussi le taux de détection)
- Chapitre "historique" : trois paragraphes commencent par "la méthode", varier un peu ? + majuscule
- Pour ma curiosité personnelle j'aurais bien aimé une précision sur "les caractéristiques sont calculées à toutes les échelles" : vraiment toutes ? toutes dans un intervalle ? un certain nombre dans un intervalle donné ?
- --Kleliboux (d) 30 septembre 2010 à 17:38 (CEST)
- Merci pour les commentaires, je vais faire les corrections indiquées, tout à fait pertinentes. Pour ta dernière remarque, c'est un peu indiqué dans l'article, mais ce n'était pas très clair, je vais retravailler le passage pour que l'on fasse plus facilement le lien. En fait, on ne fait pas de décomposition en échelle sur l'image, on travaille toujours sur l'image dans sa résolution naturelle, par contre, c'est le détecteur qui change d'échelle. On part de la plus petite résolution du détecteur (24x24), que l'on augmente progressivement avec un certain facteur multiplicatif (1.25 dans la méthode originale mais c'est paramétrable), jusqu'à ce que l'on arrive à la taille maximale, c'est à dire la taille de l'image elle-même, ou une taille fixée, si l'on a des informations a priori sur la taille max de l'objet. Mais ça fait quand même pas mal de calculs, c'est sûr... Sylenius (d) 30 septembre 2010 à 20:28 (CEST)
- Aah bah voilà quand on m'explique comme ça j'comprends :op --Kleliboux (d) 30 septembre 2010 à 23:27 (CEST)
- céfé. J'ai finalement quand même gardé une note, qui n'apporte pas une info très importante et qui aurait alourdit le texte, je trouve. Sylenius (d) 1 octobre 2010 à 17:51 (CEST)
- Si pas plus de remarques, vous êtes partants pour une présentation en BA ou AdQ ? Sylenius (d) 2 octobre 2010 à 21:46 (CEST)
- Je voudrai relire l'article (ce que je n'ai pas encore pu faire complètement). Mais je ne pourrai le faire que demain soir. --Indif (d - c) 2 octobre 2010 à 22:31 (CEST)
- pas de problème, on est pas à quelques jours près. Sylenius (d) 2 octobre 2010 à 22:47 (CEST)
- idem, j'ai été un peu en stand by la semaine passée, je m'y remet bientôt. Concernant l'article en question, outre féliciter Sylénius pour le travail effectué, j'ai repéré deux phrases qui meriteraient à être reformulées dans la partie sélection de caractéristiques:
- « L'algorithme maintient également une distribution de probabilité sur l'ensemble d'apprentissage, qui est ré-évaluée à chaque itération en fonction des résultats de classification. » une ddp existe en soi et n'est pas vraiment « maintenue ». Tu parles en fait de la répartition des poids attribués à chaque échantillon d'apprentissage, poid qui est réevalué à chaque itération en fonction de la difficulté à le classer en prenant en compte les étapes (classif faible) déjà calculées.
- « L'algorithme de boosting est constitué d'un certain nombre T d'itérations,... » C'est un algo itératif...
- Ce en quoi je relirai plus précisément dans la semaine à venir Xiawi (d) 3 octobre 2010 à 13:38 (CEST)
- idem, j'ai été un peu en stand by la semaine passée, je m'y remet bientôt. Concernant l'article en question, outre féliciter Sylénius pour le travail effectué, j'ai repéré deux phrases qui meriteraient à être reformulées dans la partie sélection de caractéristiques:
- pas de problème, on est pas à quelques jours près. Sylenius (d) 2 octobre 2010 à 22:47 (CEST)
- Je voudrai relire l'article (ce que je n'ai pas encore pu faire complètement). Mais je ne pourrai le faire que demain soir. --Indif (d - c) 2 octobre 2010 à 22:31 (CEST)
- Si pas plus de remarques, vous êtes partants pour une présentation en BA ou AdQ ? Sylenius (d) 2 octobre 2010 à 21:46 (CEST)
- Aah bah voilà quand on m'explique comme ça j'comprends :op --Kleliboux (d) 30 septembre 2010 à 23:27 (CEST)
- Merci pour les commentaires, je vais faire les corrections indiquées, tout à fait pertinentes. Pour ta dernière remarque, c'est un peu indiqué dans l'article, mais ce n'était pas très clair, je vais retravailler le passage pour que l'on fasse plus facilement le lien. En fait, on ne fait pas de décomposition en échelle sur l'image, on travaille toujours sur l'image dans sa résolution naturelle, par contre, c'est le détecteur qui change d'échelle. On part de la plus petite résolution du détecteur (24x24), que l'on augmente progressivement avec un certain facteur multiplicatif (1.25 dans la méthode originale mais c'est paramétrable), jusqu'à ce que l'on arrive à la taille maximale, c'est à dire la taille de l'image elle-même, ou une taille fixée, si l'on a des informations a priori sur la taille max de l'objet. Mais ça fait quand même pas mal de calculs, c'est sûr... Sylenius (d) 30 septembre 2010 à 20:28 (CEST)
- Remarques :
- Fin du 2e § du résumé introductif (« dans des sous-parties de l'image de seulement quelques pixels ») imprécise : doit-on comprendre que la méthode fonctionne sur des sous-parties de quelques pixels ou qu'elle est capable de détecter des objets dans des sous-parties de quelques pixels ?
- Je pense qu'il est préférable d'utiliser l'expression et son équipe à la place du trop doctoral et al.
- --Indif (d - c) 3 octobre 2010 à 22:12 (CEST)
- Remplacer la première occurrence d'un acronyme par le nom développé, par exemple : « International Journal of Computer Vision (IJCV) » à la première occurrence, puis « IJCV » aux autres occurrences.
- « c.-à-d. » au lieu de « i. e.
- La sous-section Définition de la section Caractéristiques ne devrait-elle pas s'appeler plutôt Description ou Introduction ?
- Les quantités mathématiques ne sont pas formellement définies (et toujours écrites en mode mathématique) : « Le choix du nombre d'étages est fixé par l'utilisateur, la méthode originale de Viola et Jones utilise K = 32 étages » doit plutôt s'écrire : « Le choix du nombre d'étages est fixé par l'utilisateur, la méthode originale de Viola et Jones utilise étages » .
- Quand on lit que « la méthode de Viola et Jones nécessite de quelques centaines à plusieurs milliers d'exemples de l'objet que l'on souhaite détecter, pour entraîner un classifieur », on est effaré par ce nombre. On a l'impression que pour reconnaître un objet quelconque, même le plus simple, il faut d'abord le shooter plus milliers de fois, sous toutes ses coutures !
- Les différents paramètres de la méthode sont-ils choisis uniquement par essais successifs (ce qui dans ce cas peut exiger un temps exorbitant) ou bien de manière empirique ?
- Le domaine infra-rouge fait partie du domaine optique non ? Ne serait-ce pas plutôt le domaine visible dont il est question ?
- --Indif (d - c) 3 octobre 2010 à 23:44 (CEST)
- merci pour toutes ces remarques, je vais faire les corrections (mais c'est pas toujours facile de reformuler).
- pour tes questions:
- on a effectivement besoin de plusieurs milliers d'exemples pour que ça marche bien, non pas sous touttes ses coutures (on apprend qu'une seule vue en plus) mais bien un ensemble le plus exhaustif possible de cas que l'on peut rencontrer.
- essais successifs: j'ai mis un renvoi vers l'interwiki en:trial and error, c'est par essais successifs de paramètres que l'on trouve une bonne combinaison (et non pas LA bonne combinaison, car il n'est pas possible d'être exhaustif) donc c'est bien empirique. Sylenius (d) 4 octobre 2010 à 11:40 (CEST)
- @Xiawi, sur ta remarque « L'algorithme de boosting est constitué d'un certain nombre T d'itérations,... » C'est un algo itératif... je n'ai pas trop compris ce que tu voulais changer, tu le fais ? Sylenius (d) 4 octobre 2010 à 11:47 (CEST)


Je viens de terminer la relecture de l'article. Le label BA (au minimum) lui tend les bras. Il reste quand même quelques détails à régler ![]() , dont voici la (courte) liste :
, dont voici la (courte) liste :
- Application des modèles {{Ouvrage}}, {{Article}} et {{Chapitre}} aux références. Je m'en charge.
- Je ne nie pas la grande importance de la courbe ROC. Je continue néanmoins de croire que le format taille réelle centré pleine page convient plutôt à une publication dans une revue scientifique, mais intéressera à peine ici le lecteur lambda. (Mais attention, ce n'est qu'une question de goût personnel )
- Bien sûr, réduire au maximum le nombre de liens rouges.
- Uniformiser l'écriture de certains termes : taux de détection ou détections ? taux de fausse alarme ou fausses alarmes ?
- Le terme « essais et erreurs » est celui qui correspond le mieux à « trial and error ». On adopte ?
Ce sera tout pour ce soir ![]() . --Indif (d - c) 7 octobre 2010 à 21:32 (CEST)
. --Indif (d - c) 7 octobre 2010 à 21:32 (CEST)
- ok
- le laisser en thumb n'a que peu de sens je trouve, puisque l'on ne voit strictement rien, et que c'est quand même l'information intéressante du paragraphe. De plus ça reste quand même assez facile à comprendre, un pourcentage de bonne détection, c'est assez parlant, même pour un néophyte. Dans les bonnes pratiques sur les images WP:IMG, on dit bien que les schémas peuvent être pleine page, c'est amha l'un de ces cas.
- je vais me charger d'un certain nombre de liens rouges
- c'est toujours pénible ça Au singulier ?
- j'aime pas, mais j'ai rien de mieux à proposer. Dans le texte et pour la lecture, je préfère quand même nettement essais successifs, bien plus français, mais pas question de choisir ça comme titre d'article. Sylenius (d) 7 octobre 2010 à 23:06 (CEST)
- Ok
- Ok
- Sus aux liens rouges !
- Je ne sais pas pourquoi, mais je suis attiré par « taux de détection » et « taux de fausses alarmes » .
- D'autres ont fait le choix pour nous : essais et erreurs.
- --Indif (d - c) 8 octobre 2010 à 07:50 (CEST)
- L'application des modèles {{Ouvrage}}, {{Article}} et {{Chapitre}} aux références est terminée. --Indif (d - c) 11 octobre 2010 à 13:48 (CEST)
- Qu'est-ce qu'on fait ? on envoie en procédure AdQ ou cela ne vous semble pas utile ? Sylenius (d) 19 octobre 2010 à 17:15 (CEST)
 Pour --Indif (d - c) 19 octobre 2010 à 17:37 (CEST)
Pour --Indif (d - c) 19 octobre 2010 à 17:37 (CEST)
- Pour aussi bien que ne connaissant pas bien le droit administratif wikipédien et la notion d'AdQ en particulier --Kleliboux (d) 21 octobre 2010 à 11:19 (CEST)
- C'est parti: Discussion:Méthode de Viola et Jones/Article de qualité et il est toujours de temps de faire des remarques. Sylenius (d) 27 octobre 2010 à 23:35 (CEST)
- Qu'est-ce qu'on fait ? on envoie en procédure AdQ ou cela ne vous semble pas utile ? Sylenius (d) 19 octobre 2010 à 17:15 (CEST)
- L'application des modèles {{Ouvrage}}, {{Article}} et {{Chapitre}} aux références est terminée. --Indif (d - c) 11 octobre 2010 à 13:48 (CEST)
SIFT[modifier le code]
Il y a encore du travail sur l'article, mais à mon avis il n'est pas loin d'atteindre son point de stabilité. Quel potentiel lui voyez-vous : AdQ ![]() , BA
, BA ![]() ou rien
ou rien ![]() ? Cela vaudrait-il le coup de lancer dès maintenant l'étape de pré-proposition à un label ou est-il préférable d'attendre, la précipitation étant mauvaise conseillère ? --Indif (d - c) 6 novembre 2010 à 18:11 (CET)
? Cela vaudrait-il le coup de lancer dès maintenant l'étape de pré-proposition à un label ou est-il préférable d'attendre, la précipitation étant mauvaise conseillère ? --Indif (d - c) 6 novembre 2010 à 18:11 (CET)
- je l'ai pas lu ! laisse-moi quelques jours pour le lire en détail. Sylenius (d) 6 novembre 2010 à 18:55 (CET)
- Bien volontiers . --Indif (d - c) 6 novembre 2010 à 19:14 (CET)
- Bien volontiers
- un truc m'échappe dans la partie Détection d’extrémums dans l’espace des échelles, c'est pourquoi la division de la résolution de l'image par 2 revient à doubler le facteur d'échelle ? ça ne serait pas plutôt que lors du passage à l'octave suivante (doublement du ) on sous-échantillonne l'image par 2 avant d'appliquer les convolutions ? Sylenius (d) 9 novembre 2010 à 11:29 (CET)
- Pour la présentation en BA, il me semble qu'il manque quelques liens rouges importants: différences de gaussiennes, espace échelle, sinon ok. Sylenius (d) 9 novembre 2010 à 14:32 (CET)

- Les octaves sont en fait une sorte de vue de l'esprit : l'espace des échelles est continu, et le sous-échantillonnage de l'image, à intervalles régulier, permet d'économiser une convolution.
- Ni le label BA, ni le label AdQ n'exigent que tous les liens soient bleuis : ils doivent être seulement être limités, et à mon avis concerner des éléments connexes de moindre importance (le lien image intégrale doit être bleu, car nécessaire à la compréhension d'un aspect important de l'algo, mais pas GLOH, qui n'est qu'une solution concurrente parmi d'autres).
- Qu'est-ce qui manque pour l'AdQ ?
- --Indif (d - c) 9 novembre 2010 à 15:27 (CET)
- je vois bien que l'on discrétise l'espace des échelles, mais je ne comprends pas cette équivalence entre division de la résolution de l'image par 2 et doublement du facteur d'échelle, ou le fait qu'un sous-échantillonnage remplacerait une convolution ?? Pour moi, c'est indépendant. Ce que je comprends de la méthode, c'est qu'à l'intérieur d'une octave, disons entre et , on applique un certain nombre de convolution et qu'ensuite pour l'octave suivante, de à , on applique ces convolutions sur une version sous-échantillonnée de la sortie de la première octave. C'est pas ça ?
- différences de gaussiennes et espace échelle me semblent justement être trop importants pour être laissés en rouge, même pour un BA. Il faut également réfléchir à la pertinence de certains liens rouges. Je ne suis pas sûr que GLOH par exemple, mérite un article.
- Pour l'adQ, même chose que pour le BA mais en pire pour les liens rouges, en particulier pour les applications, et notamment celle qui est l'une des plus importante à l'origine pour Lowe: l'assemblage d'images (panorama). Enfin, il faudrait cette partie historique/recul dont on parle plus haut. C'est pas infaisable Sylenius (d) 9 novembre 2010 à 16:03 (CET)
- Je passe le relai à kleliboux, de peur de dire des bêtises.
- Je compte bleuir le maximum de liens pertinents. Mais le 14, c'est dans quelques jours, et j'ai 3 arbitrages en cours...
- La page en:Image stitching est ouverte dans un onglet de mon navigateur depuis hier !
- --Indif (d - c) 9 novembre 2010 à 16:33 (CET)
- L'arrêt du wikiconcours ne signifie pas forcément l'arrêt du travail sur les articles. Rien n'empeche de proposer au label après le 15 si ce n'est pas terminé (il n'y a pas de bonus au label dans le WCC !). Bon courage pour les arbitrages
 ... et pour image stitching ! Sylenius (d) 9 novembre 2010 à 16:38 (CET)
... et pour image stitching ! Sylenius (d) 9 novembre 2010 à 16:38 (CET)
- L'objectif est de présenter un article terminé, et un article terminé est un article potentiellement labellisable. CQFD . --Indif (d - c) 9 novembre 2010 à 16:44 (CET)
- Sur la notion d'AdQ, je vous laisse juges. Sur la notion d'octaves, c'est simple. Dans le calcul d'une convolée, si je double le sigma, le calcul met 4 fois plus de temps puisque le filtre gaussien double de taille dans chaque dimension. Si, au lieu de cela, je commence par diviser l'image par 2 et que je laisse le sigma inchangé, j'obtiens le même résultat mais moins précis puisque dans une résolution inférieure ; ceci en 4 fois moins de temps. D'une façon générale, il est débile de calculer un flou gaussien avec un grand sigma, parce qu'alors la taille du filtre étant très grande, ça prend beaucoup de temps. Or plus on floute moins on a besoin de précision... En termes mathématiques (si D est l'opération de division de la taille de l'image par 2), on a une commutation de l'opérateur de convolution selon la formule : , le premier membre étant quasiment 16 fois plus rapide à calculer que le second.
- Pour corriger Indif qui a presque raison, il faudrait dire « Les octaves sont en fait une sorte d'astuce pratique de calcul : l'espace des échelles est continu, et le sous-échantillonnage de l'image, à intervalles réguliers, permet d'économiser en temps de calcul en réduisant la taille du filtre gaussien dans la même proportion ». --Kleliboux (d) 9 novembre 2010 à 17:37 (CET)
- J'ajoute un exemple. Si un point-clé est détecté sur la 2ème octave, c'est à dire sur une image qui s'écrit (moins la différence du gradient suivant - car on travaille sur des DoG), son facteur d'échelle caractéristique va être puisqu'on l'aurait théoriquement détecté sur l'image de départ en covolant avec le filtre , conformément à la formule ci-dessus... De la même façon que l'on va doubler la valeur de ses coordonnées et pour se rapporter à l'image de départ, avant de le stocker... Euh suis-je si clair ? --Kleliboux (d) 9 novembre 2010 à 17:47 (CET)
- Ok ! compris. Merci ! Sylenius (d) 9 novembre 2010 à 18:01 (CET)
- Bonjour à tous. C'est encore l'impatient de service ! J'ai encore fait une relecture de l'article hier, et il reste les liens rouges suivants : robotic mapping, assemblage de panorama, reconnaissance de mouvements, shape context, modèle de sac de mots, détecteur de coins, FAST et arbre de vocabulaire évolutif. Que doit-on obligatoirement bleuir, déwikifier parce qu'inutile ou laisser tel quel parce que pas urgent ? Pour ma part, dès que je termine Différence de gaussiennes, je m'attaque à la traduction d'en:Image stitching. --Indif (d - c) 18 novembre 2010 à 09:29 (CET)
- Bonjour à tous. C'est encore l'impatient de service !
- Ok ! compris. Merci ! Sylenius (d) 9 novembre 2010 à 18:01 (CET)
- L'objectif est de présenter un article terminé, et un article terminé est un article potentiellement labellisable. CQFD
- L'arrêt du wikiconcours ne signifie pas forcément l'arrêt du travail sur les articles. Rien n'empeche de proposer au label après le 15 si ce n'est pas terminé (il n'y a pas de bonus au label dans le WCC !). Bon courage pour les arbitrages








Détection de personne[modifier le code]
On peut commencer une relecture sur cet article également. Il ne me reste plus que la partie modèles pour la classification à terminer, le reste devrait être stable. Sylenius (d) 7 novembre 2010 à 10:04 (CET)
- Après une première lecture rapide, je dirais que l'article est vraiment extra "mais" qu'il ne détonerait pas dans un état de l'art de thèse récent (citations CVPR et ICCV 2009...). Perso, je suis favorable à laisser ces résultats récents si tu penses qu'ils sont suffisamment sérieux (a priori ils en ont l'air) mais ils ne sont vraiment pas loin de la présentation de travaux originaux de recherche, donc limites pour WP. Mais comme le sujet est de toute façon assez pointu, je répète que je trouve pertinent de le laisser. Xiawi (d) 13 novembre 2010 à 19:35 (CET)
- Je ne suis pas spécialiste mais est-ce que la soustraction de fond est vraiment strictement limitée aux caméra fixes? Par exemple, n'existe-t-il pas des cas où le fond est suffisamment régulier pour être soustrait? Je pense à un parking (ou un match de foot) pour lequel le fond peut certes varier un peu mais rester suffisamment semblable lors d'un travelling pour être soustrait. Non??? Xiawi (d) 13 novembre 2010 à 22:00 (CET)
- Alors sur les références de 2009 et 2010, il n'y a presque que des thèses dont j'utilise l'état de l'art, ou des survey/benchmark, donc pas de travaux originaux récents. Utiliser des synthèses récentes de l'existant est par contre un avantage . Il n'y a qu'un seul article de 2009, utilisé comme en ref sur un point d'amélioration ( l'utilisation combinée des HOG et LBP) , je considère que c'est ok dans le cadre de WP, je ne vois pas vraiment de brèche au TI dans ce cas, mais tu as raison de faire attention au problème.
- Sur la soustraction, je m'étais fait une réflexion similaire quand je découvrais la technique, mais je ne crois pas que cela soit possible, déjà que les résultats sont loin d'être parfait, rajouter du bruit en supposant que le fond est uniforme (ce qui n'est presque jamais le cas) lors d'un travelling ou zoom ne va pas aider. La moindre structure va générer un artefact et il faudrait en plus que le travelling soit très lent. Autant utiliser plusieurs caméras, ou une grand angle, ou une 360°, ça sera plus efficace. Sylenius (d) 19 novembre 2010 à 21:42 (CET)
- Alors sur les références de 2009 et 2010, il n'y a presque que des thèses dont j'utilise l'état de l'art, ou des survey/benchmark, donc pas de travaux originaux récents. Utiliser des synthèses récentes de l'existant est par contre un avantage
Schémas[modifier le code]
Illustration 1[modifier le code]
Bonjour à tous. Je vous propose de remplacer le schéma des caractéristiques de Viola et Jones au format PNG par un schéma au format SVG :
-
 Caractéristiques de Viola et Jones
Caractéristiques de Viola et Jones -
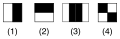 Proposition au format SVG
Proposition au format SVG

{kind=link}
{kind=link}
{kind=link}
Cdlt. --Indif (d - c) 4 octobre 2010 à 10:38 (CEST)
- c'est mieux oui, et ressemble à celui que tu as fait pour les caractéristiques étendues, du coup, c'est plus homogène. Sylenius (d) 4 octobre 2010 à 11:40 (CEST)
Illustration 2[modifier le code]
J'ai repris le schéma de la courbe ROC : simplification de tracés, vectorisation du texte, suppression de la légende en tête, repositionnement des légendes des axes. --Indif (d - c) 4 octobre 2010 à 12:58 (CEST)
Illustration 3[modifier le code]
J'ai repris le schéma de l'architecture en cascade :
.svg)
- il faudrait rajouter les lettres V (Vrai) et F (Faux) sur chaque flèche, parce que tel quel, je le trouve difficile à comprendre. Je préfère aussi que chaque flèche de rejet aille vers la case rejet, c'est plus clair, surtout que le fait de mettre la case rejet à la fin, on a l'impression que la décision de rejet n'est faite qu'à la fin, alors que ce n'est précisément pas le cas.
- PS: N'oublie pas d'ajouter tes créations sur la page dédiée. Sylenius (d) 4 octobre 2010 à 21:55 (CEST)
- Et là ? --Indif (d - c) 4 octobre 2010 à 22:18 (CEST)
- si tu pouvais remplacer les chiffres 1, 2, 3 par étage 1, étage 2, étage 3, ce serait parfait
 . Sylenius (d) 4 octobre 2010 à 22:29 (CEST)
. Sylenius (d) 4 octobre 2010 à 22:29 (CEST)
- Et comme cela ? --Indif (d - c) 4 octobre 2010 à 22:49 (CEST)
- J'ai aplati le processus, cela me semble être plus parlant, plus proche de la vérité, avec le boîte rejet bien à part, en dehors du processus. --Indif (d - c) 4 octobre 2010 à 23:01 (CEST)
- Nickel. Sylenius (d) 5 octobre 2010 à 10:36 (CEST)
- si tu pouvais remplacer les chiffres 1, 2, 3 par étage 1, étage 2, étage 3, ce serait parfait
- Et là ? --Indif (d - c) 4 octobre 2010 à 22:18 (CEST)
Illustration 4[modifier le code]

J'ai supprimé de l'image le cartouche du logo. C'est pas ce qui se fait mieux en matière de retouche, mais ça passe quand même. --Indif (d - c) 6 octobre 2010 à 09:57 (CEST)
Changement d'articles ?[modifier le code]
Je me demandais si on changeait certains de nos articles principaux. En particulier Détection d'objet n'est pas si facile que ça à développer (en tout cas, moi je coince un peu), et je pense qu'il est peut être plus facile de faire quelque chose de bien d'extraction de caractéristique et/ou de détection de personne. Des avis ? Sylenius (d) 20 octobre 2010 à 18:51 (CEST)
- Je ne vois pour ma part aucun inconvénient. --Indif (d - c) 20 octobre 2010 à 21:29 (CEST)
- Je pense au contraire qu'un article de vulgarisation sur la détection d'objet est intéressant, même s'il n'est pas très fourni. La notion d'extraction de caractéristique est quand même très technique. Parmi les applications il faudrait citer la réalité augmentée et la video surveillance. Par ailleurs, contrairement à ce qui est écrit dans l'introduction, il y a une nuance entre "classification d'objet" et "détection d'objet", la première expression se rapportant à mon sens à la phase d'apprentissage nécessaire dans la plupart des techniques de détection.--Kleliboux (d) 21 octobre 2010 à 11:03 (CEST)
- Bon, on va voir comment ça évolue sur détection d'objet, mais par expérience, plus un article est général, plus il est difficile à rédiger ! Sylenius (d) 21 octobre 2010 à 19:17 (CEST)
- je n'aurais pas le temps de faire quoi que ce soit sur détection d'objet, donc je le remplace par détection de personne, bien avancé. A moins que Xiawi ne se réveille et trouve le temps de faire quelque chose sur détection d'objet ? Sylenius (d) 6 novembre 2010 à 08:21 (CET)
- j'ai supprimé également détection de visages des articles principaux, que je n'aurais pas le temps de développer d'ici la fin. je le rajoute en tant qu'article connexe. Sylenius (d) 12 novembre 2010 à 09:39 (CET)
- Oui désolé, je fus très endormi (DL CVPR le 11 novembre...). Je suis plutôt d'accord avec Sylenius, il est plus facile de faire un article fourni sur extraction de caractéristique que sur la détection d'objets. J'avance en ce sens aujourd'hui. JE suis néanmoins d'accord également avec le fait qu'un article de vulgarisation sur la détection d'objet soit intéressant, mais le faire bien est difficile, car comme expliqué actuellement chaque technique utilise qui sa caractéristique qui son algo d'apprentissage mais la recherche est encore très active. Enfin, je vais quand même avancer un peu cet article aussi. Xiawi (d) 13 novembre 2010 à 11:51 (CET)
- NB: pour la nuance detection/classification, je fais référence à la terminologie utilisée dans la littérature. PascalVOC appelle classification le fait de détecter la présence d'un objet et detection le fait de mettre une boite englobante. Idem pour Murphy et al cité dans l'article. Mais d'autres (eg Perronnin) vont l'appeler "generic visual categorization". Donc cela dépend des auteurs et c'est pourquoi j'ai indiqué souvent deux terminologies.
- Ayant un peu avancé extraction de caractéristique (il a doublé de taille ces deux derniers jours) je l'ai rajouté à la liste. Il n'est pas complet, loin de là, mais je me suis dit qu'il valait mieux ajouter un peu que pas du tout. Espérant ne pas avoir fait de bétise... Xiawi (d) 14 novembre 2010 à 23:10 (CET)
- Nan, très bien, joli sprint de fin . Je ne suis pas trop disponible en ce moment, j'essaie de répondre à tes remarques sur détection de personnes un peu plus tard. Sylenius (d) 15 novembre 2010 à 19:38 (CET) Bonne chance pour CVPR...
- Nan, très bien, joli sprint de fin
- Ayant un peu avancé extraction de caractéristique (il a doublé de taille ces deux derniers jours) je l'ai rajouté à la liste. Il n'est pas complet, loin de là, mais je me suis dit qu'il valait mieux ajouter un peu que pas du tout. Espérant ne pas avoir fait de bétise... Xiawi (d) 14 novembre 2010 à 23:10 (CET)
- j'ai supprimé également détection de visages des articles principaux, que je n'aurais pas le temps de développer d'ici la fin. je le rajoute en tant qu'article connexe. Sylenius (d) 12 novembre 2010 à 09:39 (CET)
- je n'aurais pas le temps de faire quoi que ce soit sur détection d'objet, donc je le remplace par détection de personne, bien avancé. A moins que Xiawi ne se réveille et trouve le temps de faire quelque chose sur détection d'objet ? Sylenius (d) 6 novembre 2010 à 08:21 (CET)
- Bon, on va voir comment ça évolue sur détection d'objet, mais par expérience, plus un article est général, plus il est difficile à rédiger ! Sylenius (d) 21 octobre 2010 à 19:17 (CEST)
- Je pense au contraire qu'un article de vulgarisation sur la détection d'objet est intéressant, même s'il n'est pas très fourni. La notion d'extraction de caractéristique est quand même très technique. Parmi les applications il faudrait citer la réalité augmentée et la video surveillance. Par ailleurs, contrairement à ce qui est écrit dans l'introduction, il y a une nuance entre "classification d'objet" et "détection d'objet", la première expression se rapportant à mon sens à la phase d'apprentissage nécessaire dans la plupart des techniques de détection.--Kleliboux (d) 21 octobre 2010 à 11:03 (CEST)
Questions du jury[modifier le code]
Questions de Gemini1980 (d · c · b)[modifier le code]
Bonjour,
Tout d'abord, félicitations pour avoir été retenus dans la présélection par équipe, ça prouve que de remarquables efforts ont été effectués, et c'est avant tout WP qui y gagne, mais j'espère que vous y avez pris plaisir.
Parmi mes questions, un peu bateau, mais qui permettront, je l'espère, de mettre en lumière le travail effectué :
- quels sont, selon vous, les points forts de votre équipe qui méritent une attention particulière / quels sont vos atouts ?
- sur quoi se sont portés en priorité vos efforts ?
- avez-vous des regrets à l'issue de ce Wikiconcours (manque de temps, mauvaise organisation, mauvaise communication, etc.) ?
- bonus : seriez-vous prêt à participer de nouveau à une prochaine édition (concurrent ou juré) ?
Sincères salutations. Gemini1980 oui ? non ? 27 novembre 2010 à 16:25 (CET)
- Je ne crois pas que ce soit un point fort, mais c'est ce qui m'a marqué: à part moi, c'est la première participation à un WCC pour les membres de l'équipe, un d'entre nous s'est inscrit à WP pour le concours, et un autre est peu actif en temps normal, et on ne se connaissait pas avant le concours. L'autre point est qu'au moins 3 d'entre nous sont des professionnels du domaine, et que l'on peut donc être assez confiant dans la qualité du résultat.
- à part le développement des articles principaux, l'idée était développer le thème de la vision par ordinateur sur WP, jusque là quasi-inexistant, si possible en lien avec le tout nouveau Portail:imagerie numérique.
- Non, au contraire, ça s'est beaucoup mieux passé que prévu quand j'ai lancé l'idée.
- en tant que concurrent, oui (je parle pour moi en tout cas) Sylenius (d) 4 décembre 2010 à 17:14 (CET)
Questions de Juraastro (d · c · b)[modifier le code]
Bonjour à tous !
Félicitations pour vos bons résultats lors de cette présélection qui sont la récompense des efforts que vous avez fournis pendant ce concours.
D'abord, j'aimerai savoir comment vos efforts et votre temps ont été coordonnés et utilisés ? L'équipe a t-elle rencontrée des problèmes et comment les a t-elle résolus ? Il y a t-il eu des conflits au sein de l'équipe ou avec d'autres contributeurs ?
Cordialement, Jur@astro (Causer à un jurassien dans les étoiles![]() ) 28 novembre 2010 à 13:02 (CET).
) 28 novembre 2010 à 13:02 (CET).
- Il n'y a pas eu de réelle concertation sur la coordination. Tout s'est fait naturellement, chacun contribuant dans son domaine d'expertise (sauf moi, qui ne suis qu'un pauvre chimiste de formation ). Tout s'est parfaitement bien déroulé, même si les contraintes IRL ont un peu contrarié la présence de certains. Personnellement, je ne connaissais aucun des autres membres de l'équipe, et cela n'a pas empêché la mayonnaise de prendre et d'enrichir considérablement le domaine de la vision par ordinateur, dont le contenu frisait le ridicule. Je rempilerai sans problème avec la même équipe. --Indif (d - c) 5 décembre 2010 à 10:51 (CET)
- Tout pareil. Sylenius (d) 5 décembre 2010 à 13:07 (CET)
Épilogue[modifier le code]
Même si j'arrive après la bataille à cause des contraintes IRL mentionnées plus haut, et en tant que nouveau contributeur à Wikipedia, j'ai trouvé le système motivant et je félicite l'équipe pour son prix spécial ! J'ai voté pour la promotion de l'article SIFT au label AdQ et j'aurais fait pareil pour l'article Méthode de Viola et Jones si j'avais compris le système avant, car je le trouve vraiment bien. Je suis prêt à re-collaborer avec vous à l'avenir si le temps me le permet. --Kleliboux (d) 3 janvier 2011 à 15:52 (CET)