
Utilisateur:Jurbop
Bonjour !
Vous trouverez ci-dessous des infos pratiques sur Wikipédia ! En espérant qu'elles vous soient utiles. ;)
À bientôt
Un petit trésor de ressources pratiques pour trouver des sources de qualité en ligne ? ;)[modifier | modifier le code]
Résumé avec un exemple pratique[modifier | modifier le code]
Afin d'améliorer la fiabilité de Wikipédia (fr), la communauté recommande de sourcer ses ajouts dans les articles avec des sources fiables (WP:SOURCES). Où donc trouver ces sources ?
Personnellement, en fonction du sujet et de sa période d'existence, je fais une recherche par mot clé (pensez à ajouter des guillemets lorsque vous cherchez "plusieurs" "mots clés") dans différentes bases de données. Ces bases ont numérisé des millions de documents (articles universitaires, livres et articles de presse) qui sont à votre disposition avec seulement quelques clics. ![]()
Je me rends d'abord dans celles (en français ou en anglais) qui seront probablement les plus exhaustives et qui me feront gagner le plus de temps : bases de données généralistes ou spécialisées dans un domaine précis ; le tout selon la période recherchée découpée environ comme ceci :
- à partir des années 2000 ou 2010 (documents très souvent disponibles en ligne) ?
- entre 1920 et 2000-2010 (là, il y a beaucoup moins de documents numérisés, mais on arrive quand même à en trouver) ?
- ou avant 1920 (énormément de documents numérisés, car ils sont souvent dans le domaine public) ?
Puis, s'il me manque des sources, j'essaye mes suites de différents mots clés dans d'autres bases les unes après les autres.
Exemple pratique : je souhaite rapidement sourcer un article Wikipédia en français pour la période après l'an 2000. Que ce soit une personne, une entreprise, un monument local... Je vais avoir besoin de trouver des articles de presse (journaux, magazines) ; des articles scientifiques ; des livres... Je me rends dans l'ordre sur (vous trouverez plus d'infos dans le reste de cette page pour les bases citées) :
1) Europresse : c'est la base la plus complète pour chercher dans des millions d'articles de presse en français (archives des principaux journaux et magazines). Astuce : regardez si vous pouvez y accéder à distance par le biais d'une bibliothèque d'une grande ville, et cela, même possiblement si vous n'y habitez pas ! Pensez à les appeler pour vérifier. Même si c'est souvent payant, par exemple, en fonction des municipalités, 15 euros annuels, l'avantage, c'est qu'il y a d'autres bases de données accessibles avec cet abonnement (ex: la BNF - Merci aussi à easybnf.fr ![]() ). En attendant, vous pouvez suggérer Europresse à la communauté en votant ici afin qu'elle soit ajoutée éventuellement à la carte de bibliothèque Wikipédia (plus d'explications).
). En attendant, vous pouvez suggérer Europresse à la communauté en votant ici afin qu'elle soit ajoutée éventuellement à la carte de bibliothèque Wikipédia (plus d'explications).
Une fois votre recherche effectuée, si vous avez trop de résultats, vous pouvez les trier, par exemple, en ne gardant que les résultats : d'un groupe de sources (la "presse quotidienne nationale") ; d'un journal ou magazine spécifique ; par ordre de parution, etc.
2) Carte de bibliothèque Wikipédia (cf. ci-après) : Plus d'un milliard de documents regroupés (articles universitaires, livres et articles de presse) dont 'seulement' 22,5 millions en français (en août 2022) ! En français, vous avez, par exemple, accès à Cairn, aux archives du journal Le Monde depuis 2001 (via Proquest), aux livres électroniques en français de la base Numérique Premium (plus de 6000 e-books en Sciences Humaines, Sociales, Juridiques et Politiques), etc.
3) Recherche Google simple ou en "Mot à mot" (cf. rubrique "Outils", puis "Mot à mot") avec "mots clés". Ce choix de mot(s) clé(s) a l'air de rien, mais il est très important. Selon vos choix et à force de tâtonnements, vous pouvez ne rien trouver ou tomber sur des pépites ! Exemple : "Prénom Nom" + "telle autre personne" ou avec un mot clé précis qui sera présent sur le document désiré.
Pensez aussi aux autres résultats qui s'affichent rarement dans les résultats de Google, mais disponibles sur Google livres (Voir la rubrique "Plus" dans votre recherche Google). Cela peut vous permettre de trouver des ouvrages bien ciblés. Il est à noter que les équipes de Google Livres sont celles qui ont numérisé le plus de livres au monde : 30 % des 130 millions de livres existants dans le monde (soit tout de même 40 millions de livres numérisés) !
Suggestion de Malik2Mars : « Vous pouvez aussi, sur votre brouillon, par exemple, utiliser le modèle {{trouver des sources}} et ajouter les mots clés en paramètre 1. Ce modèle génère plusieurs liens de recherche comme Google, Google Books, Google Scholar, etc. ».
4) Archive.org avec l'option « search text content » (« chercher dans le contenu texte ») que l'on trouve en cliquant dans la boite de dialogue où il y a écrit "Search". Là encore plusieurs millions de livres et autres documents numérisés (38 millions) dont 0,7 million en français (en novembre 2022) !
5) Petit moteur de recherche Google personnel. Il se limite aux archives des 20 sites de presse française les plus utilisés sur Wikipédia en français : https://cse.google.com/cse?cx=7e832251b2f0f481e.
6) Recherche éventuelle dans ma petite base de données personnelle (cf. plus bas : "Vous pouvez numériser vous-même des documents...").
Concrètement, j'ai créé un dossier dans les favoris de mon navigateur internet (Google Chrome, Firefox...) : clic droit sur le dossier et j'ouvre les 5 favoris d'un coup dans une nouvelle fenêtre de mon navigateur. Puis je copie/colle (CTRL+C puis CTRL+V) dans chaque boite de dialogue le ou les "mot(s) clé(s)". ![]()

Voici les urls dans mon cas : Europresse (via Pass Culture BNF payant) ; Carte de la Bibliothèque Wikipédia ; Google Livres ; Archive.org (avec "Search Text Content") et Contenus Google des principaux sites de presse fr.
Exemple (test sur ma page brouillon ; vous pouvez utiliser la votre) si vous voulez sourcer une information avec un article de presse en ligne (en utilisant mon petit moteur de recherche qui liste uniquement les contenus Google des principaux sites de presse fr ; lien de l'article) :

Vous vous rappelez peut-être la maman de Forrest Gump qui disait : « La vie, c'est comme une boîte de chocolats : on ne sait jamais sur quoi on va tomber » ? Et bien pour les résultats de vos requêtes, c'est pareil ! ![]()
Si finalement, vous avez besoin d'un livre ou d'un article qui n'est pas accessible pour vous en version numérique, vous pouvez tenter le prêt entre bibliothèques même si la bibliothèque du lieu où vous habitez est petite (cf. plus bas).
Maj 1 : Astuce pour essayer de combler le « trou » dans les archives numériques en langue française (presse et livres par ex) entre 1920 et 2010[modifier | modifier le code]
Quand on cherche des sources en français entre 1920 et 2010, et même avec des sources payantes et bien on a ... comme un vide (cf. l'exemple des USA) !
À défaut de pouvoir inciter les journaux eux-mêmes à numériser leurs archives (la plupart ont trop de difficultés financières actuellement ; Toutefois, d'autres ont déjà leurs archives numérisées, mais les ont supprimées de leur site internet ou n'ont gardé de disponible que, par exemple, les 5 dernières années ou un moteur de recherche peu fonctionnel...), on peut contourner le problème en visitant les sources de presse numérisées déjà accessibles gratuitement dans des pays francophones :
Presse numérisée Suisse : letemps.ch (de 1826 à 1998) ; scriptorium, Rero Doc, e-newspaperarchives.chet E-periodica.
Presse numérisée Québécoise : https://numerique.banq.qc.ca/ (Sont disponibles par ex : La Presse de 1884 à 2017 ; Le Devoir de 1910 à 2015 ; Le Soleil de 1896 à 2016 ; Québec Science de 1970 à 2008 ; …).
Maj 2 : Carte de la Bibliothèque Wikipédia ;)[modifier | modifier le code]
(Merci à Sujet:Vwjndp7gsamxm7kk) Wikipédia offre une carte d'accès virtuelle à la Bibliothèque Wikipédia. Vous pouvez ainsi lire de nombreux documents normalement payants ! Il suffit pour cela d'avoir effectué plus de 500 modifications au total ; contribuer depuis plus de 6 mois ; d'avoir effectué plus de 10 modifications le mois dernier et de ne pas avoir de blocages en cours. Quelques bases de données disponibles : Ebsco, Proquest, Cairn, Jstor, Gale... https://wikipedialibrary.wmflabs.org/
- Pour un petit nombre de bases de données, il y a un système de file d'attente.
- Je vous recommande :
EBSCO/« EBSCO Discovery Service » pour rechercher par mots clefs dans plusieurs des différentes bases en une seule recherche. Vous pouvez aussi connaitre la profondeur des archives pour chaque source disponible (ex : les archives de tel journal sont disponibles depuis l'année 19xx) avec EBSCO/ « Publication Finder Interface ».la barre de recherche (disponible depuis fin 2021) qui permet de chercher en une seule fois dans quasiment tous les accès disponibles (les bases indexées ont un dessin de loupe) avec la carte Wikipédia (solution basée sur « EBSCO Discovery Service ») . Une fois votre recherche effectuée, il y a un lien vers la base de données Proquest (sur la droite).
. Une fois votre recherche effectuée, il y a un lien vers la base de données Proquest (sur la droite). - Si j'avais une petite critique à faire c'est qu'il y a beaucoup de documents en anglais actuellement et donc qu'il manque des sources en français. Vous pouvez proposer les vôtres et voter pour des suggestions ici (cf. plus bas dans cet article "Pour des articles de presse généraliste, spécialisée ou locale plutôt récents" ou Le Bistro du 4 mars ou du 25 avril 2021).
- Évolution du nombre de documents disponibles (Cela reste à mon avis une estimation à plus ou moins, car il peut y avoir des doublons dans les résultats ; tous ne sont pas forcément accessibles ! ; et certaines bases ne sont pas incluses comme Proquest ou quelques autres) : 750 millions en octobre 2021 ; 1 milliard en février 2022 ; 1,2 milliard le 5 août 2022 (dont 203 millions "relus par un comité de lecture" ; Il y a environ 500 millions de documents qui proviennent de la base Gale ; 31 millions de livres ?? Euh, à mon avis, le chiffre comporte aussi certaines critiques de livres !) la plupart des documents sont en anglais et 22,5 millions de documents sont en français dont 2,6 millions "relus par un comité de lecture").
- On ne peut pas savoir quelles bases de données seront retirées ou ajoutées au fils du temps (voir phabricator pour les prochains ajouts) !
- Astuce : si vous êtes abonné au Pass Culture de la BNF, le contenu des bases de données disponibles dans Ebsco, Gale et Proquest ne sont pas forcément identiques ! Il faut donc essayer votre recherche avec la Carte de la Bibliothèque Wikipédia et le Pass BNF ! J'ai déjà eu de belles surprises ! De la même façon que pour la Carte de la Bibliothèque Wikipédia, la BNF permet également de chercher dans plusieurs bases de données de son Pass simultanément : https://bdl.bnf.fr/ (ajouter vos mots clés dans la boite de dialogue bleue). Parmi les bases non indexées, je vous suggère : Proquest (accès à 4 bases pour la Carte de la Bibliothèque Wikipédia contre 16 pour le Pass BNF), Generalis et Delphes (extraits d'archives de presse fr depuis 2000 environ) ; "Cyberlibris (ex-Scholarvox)" (plusieurs dizaines de milliers de livres numériques en français de niveau universitaire, sur l'Histoire, les Sciences Humaines et Sociales, la Psychologie-Sociologie... nb: il y a des listes d'ouvrages recommandés par des universités).

Des millions de livres ou documents numérisés : des plus récents au plus anciens (domaine public)[modifier | modifier le code]
Ajoutez des liens (« Lire en ligne » cf. Insérer/Modèle/Ouvrage ou Article) ou de nouvelles sources dans Wikipédia grâce à des millions de livres ou documents numérisés récents ou du domaine public (il peut paraître surprenant que de nombreux documents français anciens (quelquefois en couleur !) soient disponibles dans des bases de données américaines(*) ).
Exemple (test sur ma page brouillon ; vous pouvez utiliser la votre) si vous voulez ajouter un livre à partir de son numéro ISBN (c'est le numéro du code barre souvent indiqué sur la dernière page de chaque livre depuis environ 1980 pour la France) en utilisant le bouton "Sourcer" de l'éditeur visuel :

Livres récents : Carte de bibliothèque Wikipédia : plus de 30 000 livres de qualité et récents disponibles en français ! :[modifier | modifier le code]
Imaginez : vous vous promenez dans une très grande bibliothèque. Vous voyez toutes ces rangées de meubles classés par thème. Leurs étagères sont pleines de livres du sol au plafond. Et bien pas besoin de vous déplacer ! Grâce à la Carte de bibliothèque Wikipédia, non seulement vous pouvez regarder tous ces livres, mais vous pouvez aussi les lire ! Ils n'attendent que vous pour sourcer Wikipédia ! ![]()
Cairn : plus de 17 600 livres récents en français (plus 1 700 livres des collections "Que Sais-je / Repères" et 586 Revues). Disciplines : Arts ; Droit ; Économie, Gestion ; Géographie ; Histoire ; Info, Communication ; Intérêt général ; Lettres et linguistique ; Philosophie ; Psychologie ; Santé publique ; Sciences de l’éducation ; Sciences politiques ; Sociologie et société ; Sport et société.
Numérique Premium : plus de 6 300 livres récents en français. Disciplines : Économie-Gestion ; Méthodes de langues ; Préparations aux concours ; Atlas ; Droit ; Études cinématographiques ; Études de la littérature francophone ; Études philosophiques ; Géopolitique ; Histoire ; Sociologie et histoire des médias ; Psychanalyse ; Psychologie ; Sciences des religions.
OpenEdition Books : plus de 11 000 livres récents accessibles en français (plus 600 revues...). Disciplines : Arts et humanités ; Éducation ; Études environnementales, géographie et développement ; Histoire et archéologie ; Sciences de l'information et de la communication, bibliothéconomie ; Pluridisciplinarité ; Sciences politiques, administration publique et développement ; Psychologie ; Sciences de la santé et de la santé publique ; Travail social et politique sociale ; Sociologie et anthropologie ; Langue et linguistique ; Économie ; Droit ; Littérature ; Management et administration ; Psychiatrie.
Ps : Si vous êtes en France, vous avez accès au Pass lecture / culture de la BNF (24 €/an) (bis), qui propose, entre autres magnifiques bases (petit extrait), la fabuleuse base niveau universitaire de livres récents : "ScholarVox Universités" : 57 000 livres en français (dont environ 10 000 romans) sur les 78 000 livres disponibles ! Thématiques : Arts ; Caraibes ; Documentation hospitalière ; Emploi, métiers et formation ; Géographie ; Histoire ; Informatique ; Lectures loisirs ; Lettres ; Philosophie ; Psychologie Sociologie ; Santé, Sciences de la Vie et Médecine ; Sciences Eco Gestion ; Sciences de l’Éducation INSPE ; Sciences Politiques ; Sciences Religieuses ; Sciences de l'ingénieur ; Sciences Humaines et Sociales ; STAPS.
Regardez, on ne sait jamais, il est également possible que votre bibliothèque locale propose un accès à BiblioVox (à peu près le même nombre de livres en français même si c'est une version plus généraliste de ScholarVox Universités).
(bis) je n'ai pas d'actions chez eux ! L'accès à des bases de données en ligne similaires existe avec d'autres bibliothèques nationales : ex : Belgique,... ![]() Source : le Bistro du 14/01/2023.
Source : le Bistro du 14/01/2023.
Documents ou livres faisant partie du domaine public :[modifier | modifier le code]
Selon les mots-clefs choisis ("mots clefs"), vous pouvez aussi bien tomber sur des informations concernant votre commune, qu'un scientifique célèbre, etc.
- (vous devez déjà connaître !) : Google Books (Google Livres) ou ici (il faut être connecté avec son compte Google pour lire des extraits), Gallica (permet aussi de lire le début, soit 15 %, de certains livres relativement récents (à priori consultables si vous êtes dans les locaux de la bnf ![1] ). Il existe un nouveau service gratuit, indépendant de la BnF, d'alertes par mail : http://gallica-alertes.fr/), et Europeana (Gallica partiellement (?) incluse - On peut également se limiter aux sources de presse numérisée(et [1]) ou encore https://www.omnia.ie/). Si le livre est en format Kindle, vous pourrez peut-être lire son début sur Amazon Livres (
il existait avant la possibilité de chercher par mots clefs à l'intérieur de tout le contenu des millions de livres qu'ils avaient scannés et qui n'étaient pas des ebooks, mais la fonction semble avoir disparue !) - Archive.org (Utilisez la fonction « search text content » qui est très puissante, car elle permet des recherches par mots clefs dans tous les millions de documents qu'ils proposent ! Ce site propose également beaucoup d'autres choses : comme la recherche par mots clefs dans la première page principale du premier exemplaire de tous leurs sites archivés. Cf option « Search archived web sites » ! ). Archive.org propose aussi de limiter sa recherche aux livres qu'ils ont numérisés : https://openlibrary.org/search/inside (cf. le bistro du 22 octobre 2022).
- Hathitrust (ce site est une énorme base pour les documents du domaine public ! 6 milliards de pages numérisées. Pensez à essayer les nouvelles fonctions de recherches avancées)
- Digital Public Library of America (DPLA) (et peut-être https://www.wdl.org/fr/)
- Le Moteur Collection du ministère de la culture français (contient beaucoup de photos, mais aussi des documents !)
- pour un énorme catalogue seulement de livres et autres : Catalogue collectif de France et aussi worldcat.org pour avoir les différentes éditions d'un livre dont celles disponibles en ligne)
- Archives Nationales FR - Salle d'Inventaires Virtuel (il y a plusieurs bases de données : LEONORE : dossiers de titulaires de la Légion d'honneur, 1800-1976 ; ARCADE : informations sur les achats d'œuvres d'art par l'État, 1800-1969 ; ARCHIM : florilège d'images numérisées de documents emblématiques ; ADAMANT : Archives nativement numériques).
- Manuscrits : Bvmm.irht.cnrs ; Biblissima; Universal Short Title Catalogue ; Arlima.
- FranceArchives (Portail National des archives) catalogue de documents d'archives ; Archives Portal Europe.
(*) Si vous connaissez une personne aux USA ou si vous pouvez avoir une adresse IP américaine, par exemple, par votre navigateur internet (VPN), vous obtiendrez beaucoup plus de résultats sur hathitrust ou Google Books par exemple. En effet, sur les plateformes américaines, la loi américaine du copyright s'applique (domaine public souvent avant 1923, mais ça peut aller jusqu'à 1963 dans certains cas) et comme ils ne peuvent être sûrs que ce soit pareil dans votre pays, ils bloquent l'accès aux adresses IP hors des USA !
Pour des articles scientifiques :[modifier | modifier le code]
https://www.academia.edu/ ; https://isidore.science/ ; https://www.persee.fr/ ; scinapse.io ; ScanR ; Google Scholar ; Unpaywall.org (cf. Unpaywall) ; Internet Archive Scholar; https://core.ac.uk/ ; https://1findr.1science.com/ ; d'autres sites ici.
Outils pratiques dédiés aux personnes qui lisent la recherche scientifique :[modifier | modifier le code]
Research Rabbit ; Mendeley (alternatives) ; Dimensions.ai (lien direct app) ; Altmetric (vidéo avec script); Zotero (Merci à Pline).
Pour des vieilles émissions TV ou radio :[modifier | modifier le code]
Vous avez probablement déjà cherché vos mots clés dans Google rubrique "vidéo" ! Vous avez également peut-être déjà accès à des bases de données audio ou vidéo par votre bibliothèque locale, départementale, de la grande ville la proche de chez vous, par la carte de bibliothèque Wikipédia, par le Pass Culture de la BNF, etc.
https://www.ina.fr/ (et recherche avancée) avec sa super base de données gratuite : http://inatheque.ina.fr/ (accès aux vidéos et aux sons possibles dans certaines bibliothèques partenaires http://www.inatheque.fr/fonds-audiovisuels.html - possibilité de chercher dans le fonds "écrits" : ex : archives des programmes tv, archives de Télérama, ...). Gratuit : http://www.aparchive.com/, https://reuters.screenocean.com/ (actualités - ou ici), https://www.rts.ch/archives/, (Gaumont Pathé Archives), http://collections-search.bfi.org.uk/web (pour les filmographies avec possibilité de chercher dans des articles liés), BBC Archives (audio et vidéo dont environ 2 % disponibles en ligne), http://archives.ecpad.fr/, Base de données de l'atelier des archives, autres.
Pour ajouter des images :[modifier | modifier le code]
https://search.creativecommons.org/ ; https://pixabay.com/; https://www.flickr.com/ https://www.flickr.com/creativecommons(Merci à Malik); Wikipédia:Ressources libres#Photos ; https://bibliotheque.cegeptr.qc.ca (pdf) ; http://sdis.inrs.ca/trouver-images-libres-de-droits ; Search 1.56 million historic newspaper photos using Newspaper Navigator! (Chronicling america)
Vous avez l'image et vous voulez savoir à quoi elle correspond (lieu, personne,etc.) ou trouver une copie de meilleure qualité ? Essayez :
TinEye Reverse Image Search (Merci Malik) ou Google Image (vous pouvez y transférer une image).
Pour des articles de presse généraliste, spécialisée ou locale plutôt récents :[modifier | modifier le code]
- depuis 2000 : Europresse : C'est, à ma connaissance, la base la plus complète en français. De plus, Europresse permet également très souvent de voir les archives de journaux ou magazines en fac-similé (photo d'origine). Si je reprends la liste des sources de presse les plus utilisées sur fr.wikipedia.org : Le Monde (depuis 1944 ou
19872001 selon les options de votre accès). À noter : d'après mon expérience, la recherche est étonnamment plus exhaustive que sur le site du journal lui-même ! , Le Figaro (1996), Le Parisien (1998), Libération (1995), Ouest France (2003), L'Express (1993), Le Point (1995) Les Echos (1991), L'Obs (2003), La Croix (1995), Sud Ouest (1944)... Pays francophones : Radio Canada (2005), La Presse (1985), Le Soir (1997), Le Temps (1998), Le Devoir (1992), Tribune de Genève (2005) ; Sources anglaises : The Economist (2005), The Telegraph (2010), The Independent (2010). Dans certains cas, vous pouvez remarquer que les archives couvrent ce qui est disponible pour un accès abonné à un journal ou magazine. Toutefois, ce n'est pas toujours le cas ! Il y a également pas mal de journaux et magazines spécialisés et même de la presse locale française. Vous pouvez rechercher par mot clé ou carrément lire la page photo du journal pour la date que vous avez choisie. À noter : l'accès est capricieux, car il faut souvent se connecter deux fois pour y accéder !
Dans le Bistro du 8 octobre 2021, j'ai publié un "Petit comparatif de la profondeur des archives de presse fr disponibles avec la carte de bibliothèque Wikipédia" avec 2 tableaux :
.png)
.png)
Raccourcis rapides vers les plus grandes profondeurs d'archives (vous ne pouvez pas forcément lire les articles en entier, mais vous pouvez toujours faire des recherches par mots clés gratuitement) : Le Monde (depuis 1944) ; Ouest-France (25 millions d'articles depuis 1890); Sud Ouest (depuis 1944).
- Archives de journaux et magazines à partir de 2010 : Cafeyn (sorte de service de streaming de la presse). Probablement accessible grâce à votre bibliothèque locale. Ils ont ajouté, de mémoire, depuis l'été 2020, les archives numériques de beaucoup de leurs titres. Amha, il manque une vraie recherche avancée par date(s) précise(s) et/ou titre(s)). Nb: selon les abonnements des bibliothèques, il peut y avoir plus ou moins de titres de presse de disponibles.
- autres : epresse.fr ; IndexPresse (fr ; profondeur d'archives possiblement aussi grande que celle d'Europresse pour la presse fr ! Permet aussi l'accès à des résumés d'articles avec Delphes ou Generalis) ; Tagaday (anciennement Pressedd + cf. p71 de ce pdf) ; Pickanews (fr) ; PressReader (en)(plutôt orienté anglais, mais pas mal de titres fr dispo. Possiblement disponible grâce à votre bibliothèque) nb: inclus avec le Pass BNF avec une année d'archives (j'aurais aimé plus !); Factiva (surtout les actualités anglaises de Dow Jones); NexisLexis ;
Youboox. - CSE : un petit moteur de recherche personnalisé limité à vos sites préférés : pour info, pour les personnes qui le souhaitent, vous pouvez gratuitement vous créer un petit moteur de recherche personnalisé fondé sur la solution de Google : CSE "Moteur de recherche personnalisé Google" (https://cse.google.com/cse). Je vous partage cet exemple : Petit moteur de recherche dans les 20 sites les plus utilisés sur fr-wiki de la catégorie "Presse française". (Merci à Wikirider pour la liste) : https://cse.google.com/cse?cx=7e832251b2f0f481e
- Vous pouvez aussi tenter une recherche dans Google Actualités (il y a aussi une partie "News showcase" qui permet d'accéder gratuitement à une sélection d'articles payants).
Pour des vieux articles de presse scannés (environ avant l'an 2000) :[modifier | modifier le code]
- Les gratuits :
En français ces sites sont excellents :
Presse numérisée Suisse : letemps.ch ; scriptorium, Rero Doc, e-newspaperarchives.chet E-periodica (Merci à Sujet:Vwjnldvle8d3762e)
Presse numérisée Québécoise : https://numerique.banq.qc.ca/ (Sont disponibles par ex : La Presse de 1884 à 2017 ; Le Devoir de 1910 à 2015 ; Le Soleil de 1896 à 2016 ; Québec Science de 1970 à 2008 ; …). Nb: amha l'ergonomie de la recherche dans cette base de données mériterait de s'améliorer. Toutefois, la recherche par titre est possible [2] , mais il faut sélectionner "Patrimoine Quebequois / revues et journaux" au lieu de "tout" ; Une fois son document ouvert, on peut également chercher son "mot clef" pour 2 mots clefs entre guillemets [3] en cochant "recherche par phrase" ; Pour trouver l'url : "partager lien" par ex sur twitter pour avoir le bon numéro de page ; Et une fois la source ajoutée (avec le bouton "Sourcer") dans Wikipédia, pensez à re-modifier l'url (car automatiquement elle n'est pas correcte) ! ouf!
Presse Belge : Belgicapress.be (Merci au Bistro)
Presse numérisée française : Bibliothèque de Science-Po : catalogue de dossiers de presse 1945-1981 - demande de copie d'article possible (merci à la BNF pour l'info).
Presse Allemande : Zefys
Répertoire de la Presse Locale Ancienne en France par la BNF.
EuroDocs : catalogue de liens vers des bases de données Européennes.
En anglais : https://trove.nla.gov.au/, https://www.elephind.com/, https://www.fultonhistory.com/Fulton.html (des millions de pages de vieux journaux numérisés à partir de microfilms par un particulier américain. Cf. article), chroniclingamerica.loc.gov (et https://news-navigator.labs.loc.gov/search) ; Nouvelle-Zélande : https://paperspast.natlib.govt.nz/newspapers
- Les payants : https://www.retronews.fr/ (1631-1950), http://www.britishnewspaperarchive.co.uk/, https://www.lillustration.com/ (env. 1943-1955), http://museedelapresse.com/ (magazines et journaux papier).
Astuce pour connaitre la profondeur des archives disponibles des magazines et journaux (périodiques) dans une bibliothèque près de chez vous :
https://periscope.sudoc.fr/ C'est une façon détournée de comparer les archives des périodiques disponibles dans des bibliothèques (via les "Plans de Conservation Partagée des Périodiques" ex: pdf). Astuce : Pour rechercher par titre de magazine, cliquez en bas à droite sur "Rechercher par d’autres critères".
Ex : Vous voulez trouver un vieil exemplaire papier du journal Libération non disponible sur son site internet, cliquez ici. Puis cliquez sur les petits onglets blancs (à gauche). Ils sont du type « RCR + les 2 premiers numéros du département de la bibliothèque ». ![]()
Si vous voulez avoir une vision graphique des différents noms de l'hebdomadaire Marianne par ex ; la même chose sous forme de texte dans le catalogue de la BNF.
Vous pouvez également chercher des périodiques en ligne ou non dans les bases Sudoc ou Mir@bel.
Pour retrouver des liens morts (qui ont disparu d'internet) :[modifier | modifier le code]
- À part le service, déjà intégré dans Wikipédia, http://archive.wikiwix.com/ qui est très utile,
- il y a aussi la Wayback Machine (vous pouvez également faire une sauvegarde à la demande d'une page en particulier ainsi que 50 de ses pages liées, une fois enregistré gratuitement, en sélectionnant l'option "Save outlinks" ici : https://web.archive.org/save/. Je vous conseille d'utiliser leur extension pour navigateur (Chrome,...),
- le Time Travel de Memento qui regroupe plusieurs services d'archives de sites internet.
- et aussi archive.today (fait assez rare pour être souligné, ce site est géré par un particulier philanthrope. La technique d'archivage est également différente de celle d'archive.org cf. ici "[here] Chrome, executes JavaScript, scrolls page down and up, while on WB [archive.org/web] it is just a curl download.". C'est, en effet, le cas pour les archives qui sont sauvegardées par un robot d'internet archive (c'est la principale méthode utilisée par archive.org, car elle coûte beaucoup moins cher[2]). Mais lorsque vous utilisez la page https://web.archive.org/save/, c'est une version plus complète et similaire à archive.today qui est utilisée grâce à l'émulation d'un navigateur internet[2]).
- https://arquivo.pt/ est similaire à la « WayBack Machine » d'archive.org surtout en langue portugaise, mais pas que ! ;) À noter : il permet une recherche par mot clef dans tous ses sites archivés à la différence d'archive.org qui propose une recherche que dans la première page sauvegardée de chaque site (qui est disponible dans l'option "Search archived web sites").
- https://trove.nla.gov.au/ fait de même qu'arquivo.pt pour l'Australie (il faut faire sa recherche par mot clef dans la boite de dialogue, puis descendre et cliquer dans le bouton vert à droite de la rubrique "Websites", "Search websites for").
- En France, les sites web de la télévision et de la radio sont sauvegardés par l'Ina (via l'inatheque)[3]. Les autres sites internet français sont sauvegardés par la BNF qui procède à un dépôt légal des sites internet français depuis 2006 (ou 1996 via archive.org)[4] : https://www.bnf.fr/fr/archives-de-linternet[3],[5]. Hélas on ne peut pas savoir ce qui a été sauvegardé sans se déplacer physiquement à la BNF ou dans un point d'accès en région ! Vous pouvez toutefois tenter votre chance ici ou là.
- Autre liste : ici.
Suggestion de Malik2Mars : « Notez que sur Wikipédia, il y a le modèle {{lien brisé}} ». C'est un modèle qui met le lien mort en couleur rouge, le catégorise et surtout permet à chacun de cliquer sur des services d'archives pour espérer retrouver un lien qui fonctionne (cf. exemple).
Vérifiez aussi si votre bibliothèque locale propose un accès vers des ressources numérisées.[modifier | modifier le code]
En effet, certains réseaux de bibliothèques départementales françaises proposent également des accès à des ressources supplémentaires en ligne du genre : cinéma, base de données de presse, autoformations, espaces enfants, etc. Il faut aller voir leur site internet ! Par exemple, le Service Livre et Lecture du département de Vaucluse propose : http://vivreconnectes.vaucluse.fr/ ! Certains utilisent aussi probablement le réseau Carel : https://reseaucarel.org/ (ex d'étude sur le sujet).
Les bibliothèques de grandes universités[modifier | modifier le code]
Elles disposent de budgets importants et proposent la recherche par mots-clefs dans leurs énormes bases de données regroupées. À moins d'en être membre, vous ne pourrez pas accéder directement aux articles, mais vous saurez au moins qu'ils existent ! Par exemple :
Universités américaines[modifier | modifier le code]
https://clio.columbia.edu/articles ; https://library.harvard.edu/services-tools/hollis ; https://franklin.library.upenn.edu/ ;
Université suisse[modifier | modifier le code]
https://www.graduateinstitute.ch/library/find-resources.
Universités françaises[modifier | modifier le code]
https://www.bsg.univ-paris3.fr/ ; https://sorbonne-universite.primo.exlibrisgroup.com/ ; https://focus.universite-paris-saclay.fr/ ;
https://u-paris.fr/bibliotheques/
Bibliothèques numériques patrimoniales locales (régions, départements, villes, communautés de communes, universités, Chambre de commerce et d'industrie ...)[modifier | modifier le code]
Bibliothèques numériques patrimoniales de villes, départements, régions, universités : Montpellier, Aix-en-Provence, Aix Marseille Université, Marseille ; Lyon ; En Occitanie ; Bordeaux ; Toulouse *; Auvergne* ; Autres villes ici* ou là (* merci à Антуан) ; Numistral : bibliothèque numérique patrimoniale du site universitaire alsacien; .... À mon avis, il est dommage que ces bases de données ne soient pas regroupées en une seule. Gallica regroupe les résultats de certaines. ;)
Les archives municipales de certaines grandes villes ont également des collections numérisées. Selon les villes, les liens vers la recherche par mot clé sont un peu cachés, mais on peut avoir le grand plaisir d'y trouver des bases photographiques (photos, affiches, plans...), l'état civil, des expositions virtuelles, des documents expliquant en détail et avec des sources l'histoire locale de monuments, personnages, rues… Comme bien expliqué dans cette page des archives municipales de Lyon, à terme, toutes les archives ne seront pas numérisées (environ 3 % actuellement). À ma connaissance, il n'existe pas de possibilité de rechercher dans les bases de données numérisées de toutes les archives municipales en une fois (même si france-archives centralise certains noms de fonds).
Exemples de fonds numérisés de grandes villes : Archives municipales de Lyon ; Archives municipales de Marseille ; Archives municipales de Paris ; Pensez à chercher les sites internet des archives municipales d'une ville plus petite, par exemple, autour de chez vous et vous tomberez probablement sur des surprises ! ;)
Cartes postales anciennes[modifier | modifier le code]
Voir une vieille carte postale, par exemple, d'un monument peut vous faire prendre conscience de certains points précis. Attention toutefois à ne pas les ajouter automatiquement à Wikipédia, car elles sont encore extrêmement souvent sous copyrights !
Delcampe.net ; Ebay ; Google images ; Cartorum.fr ; Collection-jfm.fr ; alamy.com ; les sites d'archives départementales et d'archives municipales, ainsi que les associations d'histoire locale (cf. aussi leurs livres éventuels), ont également souvent une collection.
Pour des vieux documents ou données économiques US :[modifier | modifier le code]
https://fraser.stlouisfed.org/
D'autres bases de données[modifier | modifier le code]
(sans ordre particulier) :
presselocaleancienne.bnf.fr ; Canadiana.ca ; swisscovery.slsp.ch/ ; opencorporates.com ; softwareheritage.org ; https://arachne.dainst.org/ ; https://www.ibiblio.org/catalog/ ; https://onlinebooks.library.upenn.edu/search.html ; https://www.vie-publique.fr/rapports ; https://www.criticalpast.com/; https://www.thefreelibrary.com/ ; https://www.eubusiness.com/ ; https://eluxemburgensia.lu/ ; Plateforme de données de la recherche de l'Institut national d'histoire de l'art.
Emprunter physiquement des livres grâce au prêt entre bibliothèques (disponible même dans certains petits villages !)[modifier | modifier le code]
Il n'y a pas que les grandes bibliothèques (grandes villes, universités...) qui permettent d'emprunter des livres physiquement grâce au Prêt entre bibliothèques (ou des documents avec la FDD "fourniture de documents à distance" pdf) !
Votre petite bibliothèque locale peut également vous transmettre des livres disponibles dans la bibliothèque de votre département.
Ex : la bibliothèque de votre village propose 5 000 livres. Toutefois, vous pouvez également y emprunter des livres disponibles dans la bibliothèque départementale (100 000 livres). Ou vous pouvez aussi vous déplacer de quelques kilomètres et accéder aux 50 000 livres du réseau de bibliothèques d'une communauté de communes. ![]()
À noter : l'accès aux documents présents dans les bibliothèques est gratuit, ce n'est que pour l'emprunt qu'il faut être inscrit.
Vous avez besoin d'une aide financière pour acheter un livre de référence non empruntable dans votre bibliothèque ?[modifier | modifier le code]
Vous pouvez en faire la demande dans le lien ci-après : [...]par exemple « le livre de référence demandé ne peut pas être emprunté dans votre bibliothèque » [...] https://meta.wikimedia.org/wiki/Wikimedia_France/Micro-financement (Demandes pour 2020/2021)
Vous pouvez numériser vous-même des documents (+ faire reconnaitre automatiquement le texte inclus dans les images numérisées avec un logiciel d'OCR : reconnaissance optique de caractères) :[modifier | modifier le code]
Pour trouver des infos ultérieurement grâce à une recherche par mots clefs. Ex : vous possédez les archives papiers de votre magazine préféré. Vous pouvez numériser, par exemple, la table des matières. Vous pouvez utiliser un scanner ou simplement la technique que j'appelle le « scanner rapide du pauvre » (qui remplace les « scanners de livres automatiques » beaucoup plus onéreux : vous avez des versions portatives, par exemple, au hasard le "CZUR Shine 800 Pro" ; ou des versions fixes professionnelles avec commandes aux pieds pour lever et baisser deux plaques de verre en forme de V et prendre deux photos simultanées des deux pages comme ceci - doc pdf ) : j'utilise un système qui tient mon smartphone à la hauteur désirée (dans mon cas un vieil "agrandisseur photo PZO Krokus" (exemple photo) dont j'ai remplacé le bras horizontal, un gros bloc carré ou rond selon les modèles, par un morceau de bois d'environ 50x8x2 cm). Grâce à une molette existante, je règle la hauteur de la barre en bois. Puis, j'y pose mon smartphone et j'utilise un logiciel Android gratuit « Easy selfie ». Ce dernier me permet de siffler pour prendre une photo tout en laissant mes mains libres de tourner les pages ! Ensuite, je transfère les photos prises sur mon ordinateur et j'utilise un logiciel d'OCR (payant dans mon cas, mais il en existe en open source : ex ou celui très puissant d'archive.org (vidéo)) pour transformer les images des pages en fichier pdf. Ensuite, j’utilise un autre logiciel (ex) pour chercher par mots clefs dans tous mes documents personnels (vous pouvez également utiliser des services en ligne du genre Google Drive qui font l'OCR automatiquement sur les 100 premières pages d'un fichier pdf ou sur tous vos fichiers images par défaut).
Ces astuces sont plutôt destinées à scanner beaucoup de pages de textes. Sinon pour le scan d'une photo, vous pouvez lire cette conversation avec Malik.
Il existe aussi un forum en anglais "DIY Book scanner" https://diybookscanner.org/forum/.
Dans la même idée, vous pouvez également constituer une base d'archives personnelles contenant, par exemple, les fichiers html de sites internet que vous avez visités. Il existe pour cela des extensions de navigateurs internet comme SingleFile, Save Page WE, etc.
Bonnes recherches à tous ! ;)
Astuces et incompréhensions dans la série : « Pourquoi Wikipédia s'acharne à faire compliqué quand on peut faire simple ? » ;)[modifier | modifier le code]
Certes, la critique est facile ! Mais bon, nous ne sommes plus sur l'internet de 2001 quand Wikipédia a été créé ! À mon humble avis, afin d'augmenter le nombre d'interventions de qualité, Wikipédia doit s'adapter en se simplifiant ! ;)
Toutefois, je reconnais bien volontiers que depuis que l'Éditeur visuel existe, l'ergonomie de Wikipédia s'est nettement améliorée (cf. cette vidéo sur youtube). Par exemple : ajouter une source automatiquement (cf. cette vidéo youtube).
Marre de ne pas comprendre comment s'y retrouver dans Wikipédia malgré votre bonne volonté ? Si comme moi il y a des petites choses pratiques qui vous gonflent empêchent de contribuer sereinement sur Wikipédia ? Ces petites astuces pourraient vous aider :
- Tout d'abord, vous voudriez bien savoir quelles sont les règles et recommandations de Wikipédia ? Désolé, mais si vous cliquez en haut à gauche des liens disponibles sur chaque page Wikipédia : « Débuter sur Wikipédia » ou sur « Aide », vous ne les verrez pas de suite ! Donc voici votre lien préféré : Wikipédia:Liste des règles et recommandations (j'ai encore du mal avec certaines, mais j'essaye de m'améliorer ! ;) )
- Vous vous demandez pourquoi il ne faut surtout pas oublier d'ajouter votre signature à chaque fois que vous répondez dans une page de discussion ? ou bien qu'il faut ajouter des « : » pour mettre joliment en forme sa réponse ? C'est parce que c'est un héritage technique du passé !
Et bien allez donc dans votre page (en haut et à droite) dénommée « Bêta » et, comme moi, soyez le un peu moins (!) en cochant simplement « Activer automatiquement toutes les nouvelles fonctionnalités en bêta ». Non seulement vous n'aurez plus besoin de signer, mais vous bénéficierez de nouvelles fonctions pratiques automatiquement. ;) Ex : Nouveau mode wikicode, Différences visuelles, Discussions structurées sur la page de discussion de l’utilisateur, Outils de discussion… D'après ma petite expérience, certes ce sont des fonctions bêta, donc en cours de développement informatique, mais jusqu'à présent pour ma part, elles sont bien assez abouties pour être utilisées par de nombreuses personnes ! ;)
- Vous voulez modifier une page Wikipédia en cliquant sur « modifier le code ». Dommage ! Il va vous falloir vos yeux bioniques sauf si .... vous ne savez pas que l'option de mettre certaines parties du texte en couleur existe (comme dans n'importe quel éditeur de texte de code informatique) ! Mais bien sûr, elle n'est pas mise en place par défaut !!! GRRR ! ;) Pour cela (merci à L'ergonomie de Wikipédia est vraiment horrible (pour les contributeurs) ), il faut aller sur « modifier le code », puis cliquer sur les 3 petits traits « options », puis sélectionner « Colorisation syntaxique » !


.gif)
- Vous avez suivi les liens ci-dessus [du 1)] et vous avez ajouté des liens (« Lire en ligne » cf. Insérer/Modèle/Ouvrage -- Modèle:Ouvrage -- ou Article Modèle:Article) dans les rubriques « Oeuvres » ou « Publications » d'une page Wikipédia (c'est super, car vous pouvez ajouter des renvois facilement en utilisant le Modèle:Sfn (équivalent modèle Harvard) et en remplissant l'option « identifiant » (ou Id) dans les 2 modèles (Exemple pratique: dans Modèle:Sfn ajouter dans les options Nom1: NOMAUTEUR puis ANNEE et dans le modèle Modèle:Ouvrage : Identifiant NOMAUTEURANNEE (sans espace ! ) cf. les images ci-après (ou simplement
ajouter le Modèle:Rputiliser pour ajouter le numéro des pages, le champ "Page" ou "Alias Pages" dans le Modèle:Sfn) ? [maj : j'avoue que je rêve d'une fonction qui soit plus intuitive : si les ouvrages listés en bibliographie/ œuvre/publication d'un article pouvaient être listés automatiquement dans "Sourcer / Réutiliser" cela serait super !] C'est bien, mais il vous reste des problèmes « existentiels » !!! tels que : dans quel ordre les trier ? Et bien la réponse est très simple : peut-être bien que oui ou peut-être bien que non ! ;) cf. Discussion Wikipédia:Conventions bibliographiques#Ordonnancement par ordre chronologique.
Wikipédia - Exemple utilisation modèle Sfn - 1ʳᵉ partie (dans le texte) 
Wikipédia - Exemple utilisation modèle Sfn - 2ᵉ partie (dans le modèle ouvrage déjà disponible dans la section Bibliographie) - Il y a des gadgets dans votre page Préférences : Spécial:Préférences#mw-prefsection-gadgets Par exemple : DeluxeHistory - ajoute des couleurs dans l'historique d'un article :

.png)
.png)

- Vous voulez tomber sur des pages au hasard, mais uniquement celles d'un portail (ou d'une catégorie) précis(e) qui vous intéresse ? C'est possible, et ça existe depuis longtemps, mais c'est tellement caché que quasiment personne ne l'utilise ! Voici un exemple pour le Portail Biographie (source avec liens permettant d'espérer changer la chose). MAJ : (d'après Wikipédia:Le Bistro/12 novembre 2020#Page au hasard et portail Cinéma) : voici un lien plus simple : Spécial:Page au hasard dans une catégorie/Random page in category
- Vous aimeriez une version plus vivante de l'aide vidéo pas à pas déjà disponible (que personnellement je trouve un peu trop professorale [4] - peut-être préférez-vous cette version de 15 minutes sur youtube ?), avec des contributeurs qui vous montrent « dans les conditions du direct » comment vous y prendre par l'exemple avec une copie de leur écran même si ces vidéos sont plus (trop ?) longues ? La bonne nouvelle est que : c'est possible et disponible depuis peu ! C'est caché ici et les vidéos sont là : https://commons.wikimedia.org/wiki/Category:Live_Twitch_de_Wikip%C3%A9dia. ;) Par exemple : Apprenez à créer et à éditer des articles Wikipédia ; Wikipédia est-elle fiable...
Vous aimeriez trouver ces vidéos directement depuis les pages d'aide là c'est peut-être en cours ..ou pas !
- Vous ajoutez un copier/coller d'un lien interne à Wikipédia dans une discussion : mais pourquoi n'est-il pas automatiquement traduit en lien raccourci ce qui faciliterait la lecture du texte ?
- Est-ce que vos messages sont sauvegardés automatiquement lors de leur rédaction ? Ça dépend ! Et si oui où ? Cf. ici
Et après on va dire qu'il m'arrive de râler ? ;)
Petits tutos (vidéos et gif animés) avec des exemples pratiques (copie d'écran « comment faire ..ceci ou cela.. sur Wikipédia ? »)[modifier | modifier le code]
- [ Formation accélérée en moins de 15 minutes à Wikipédia https://www.youtube.com/watch?v=loolTNuJ_uw ]
- Comment ajouter un lien interne dans un article de Wikipédia en mode éditeur visuel (cf onglet "modifier") : https://www.cjoint.com/doc/20_05/JEupqWNaIcD_ins%C3%A9rer-un-lien-interne-dans-wikip%C3%A9dia-tuto-.gif (ou la même chose en mode wikicode https://www.youtube.com/watch?v=qRi_SAdtliU)
{kind=link}
- Insérer une référence à Wikipédia https://www.youtube.com/watch?v=yAjn1rTa3cs
- Comment créer un nouvel article à partir du brouillon https://www.youtube.com/watch?v=WuAfhK4Ph_E
- Comment ajouter une photo sur Wikimedia Commons https://www.youtube.com/watch?v=UYsEEtu0fCE
- Comment ajouter un infobox sur Wikipédia (en mode wikicode) https://www.youtube.com/watch?v=Yu_YUfIEKVw. Plus simple en mode éditeur visuel (cf. onglet "modifier") : insérer/modèle/infobox.
- Comment créer des sections dans un article Wikipédia (en mode wikicode) https://www.youtube.com/watch?v=i20A_ioAJVo. Plus simple en mode éditeur visuel (cf. onglet "modifier") : sélectionner votre texte / cliquer sur Paragraphe et choisir le titre bon format.
- Ajouter une ligne à un tableau (dans un modèle) https://www.youtube.com/watch?v=clGV36zd-Mk (source)
https://amupod.univ-amu.fr/videos/?tag=wikipedia (Merci pour l'astuce : gadget Popups)
- Guide de contribution à Wikipédia par l'Acfas 2021 (pdf)
- Comment ajouter une note dans la section Notes de "Notes et Références" (ou plus simplement ajouter un commentaire dans les notes) ? exemple
1) ajout de ce code dans le texte de l'article : <ref group=alpha> ... texte de la note ... </ref>
2) ajout d'une section Notes sous laquelle on ajoute le code : {{Références|groupe=alpha}}
(perso, j'ai mis beaucoup de temps à comprendre les explications de cette page d'aide !)
Liens divers[modifier | modifier le code]
Les raccourcis clavier[modifier | modifier le code]
Quand vous êtes en mode édition (« Modifier ») : [[ permet d'insérer un lien interne ; {{ permet d'insérer un modèle. Cf.Aide:Raccourcis clavier. ;) Pour avoir la liste des raccourcis utilisés dans les vidéos ci-dessus du genre : WP:POV cf. Aide:Raccourcis Wikipédia. ;)
Statistiques[modifier | modifier le code]
Nombre de contributeurs actifs par mois sur https://stats.wikimedia.org/#/fr.wikipedia.org/contributing/active-editors/normal%7Cline%7Call%7C~total%7Cmonthly ou encore https://stats.wikimedia.org/#/fr.wikipedia.org/contributing/user-edits/normal%7Cbar%7Call%7C~total%7Cmonthly. Et aussi : http://fr.wikichecker.com/ ; https://xtools.wmflabs.org/ec/fr.wikipedia.org/Jurbop?uselang=fr ; http://wikirank.net/fr ; http://wikipulse.herokuapp.com/ (source : https://en.wikipedia.org/wiki/Wikipedia:Statistics)
Personnes ayant créé le plus d'articles : https://fr.wikiscan.org/?page=1&menu=userstats&usort=new_main&bot=0&detail=0
Pages populaires de la veille : https://pageviews.toolforge.org/topviews/?project=fr.wikipedia.org&platform=all-access&date=yesterday&excludes=
« Le trafic suit le principe de la longue traîne, le top 20 ne représentant qu’une infime part des visites de Wikipédia. Même si certains articles totalisent plusieurs millions de visites, l’essentiel des consultations sont faites par les deux millions d’articles consultés quelques dizaines, centaines ou milliers de fois par mois. »[6].
https://analytics.wikimedia.org/
Sources de presse les plus utilisées : ici
https://grafana.wikimedia.org/ https://guc.toolforge.org/ https://guc.toolforge.org/?isPrefixPattern=1&user=jurbop
Outils semi-automatiques[modifier | modifier le code]
- Wikiloop-doublecheck (ex Wikiloop-Battlefield) outil plutôt simple qui aide à combattre le vandalisme sur Wikipédia (version FR disponible).

- Wiper (version bêta) : Aide à corriger de façon semi-automatique des erreurs (Orthographe, grammaire, typographie...) sur Wikipédia (basé sur LanguageTool).
Autres[modifier | modifier le code]
Pour avoir une idée des articles manquants de qualité : Wikipédia:Mois du sourçage ; Projet:Qualité ; Wikipédia:Contenus de qualité ; Wikipédia:Articles vitaux ; Article sans source au hasard.
Wikipédia:Wikipédia dans les médias.
Catégorie:Article manquant de références
Infos sur l'historique d'une page. Exemple au hasard : ici
Utilisateur:Cpalp/Petits trucs utiles
Liste des dernières Annonces Wikipédia
Convention de Plan / Bas de page (décision de 2009) (Merci au Bistro). Perso, je suis embêté quand j'ajoute une référence à un ouvrage situé dans la section bibliographie. ce qui m'oblige à remonter la section bibliographie au-dessus de Notes et Références.
Liste liens rouge par portail (ex : portail entreprises).
Who is missing from Wikipedia? (blog post)
Wikipedia:WikiProject Missing encyclopedic articles
Idée à creuser ? Nouvelles techniques sur Wikipédia en anglais pour corriger des erreurs typographiques ?[modifier | modifier le code]
J'ai essayé plusieurs techniques : à la main avec le moteur de recherche interne de Wikipédia (ex: la recherche de doublon "de de". En gros, j'arrive à corriger environ 100 modifications par heure et peut-être autant de modifications potentielles ignorées la plupart rapidement, car étant pour moi des faux positifs. Merci CTRL+F et CTRL+W. nb: j'ai eu pas mal de remerciements lors de la suppression de doublons ! Autre ex avec "des des"), ou avec des outils semi-automatiques : Wiper et un peu Wikipédia:WPCleaner et AutoWikiBrowser cf. ici. Je teste aussi LanguageTool (cf. la prochaine section).
J'ai également testé (liens directs avec typos et le script de "Correct typos in one click") ce qu'il y avait de disponible sur Wikipédia en anglais : [[5]].
Si je résume bien, ils utilisent notamment 2 méthodes pour trouver des typos :
- soit en partant de dumps wikipedia et en excluant des mots du wiki dictionary ;
- soit en modifiant une lettre (ou plusieurs, peut-être en ciblant les lettres proches autour de la bonne lettre sur votre clavier : ex : d à la place de e sur un clavier AZERTY, etc.?) à des mots corrects ([6]). Ainsi, l'équipe "Typo Team/moss" a pu corriger (grâce à un logiciel crée sous Python [7]) plus de 90 000 typos en un an (cf. tableau [[8]]) !
Test du correcteur d'orthographe et grammatical : LanguageTool sur Wikipédia[modifier | modifier le code]
Depuis décembre 2020, je teste l'extension pour Google Chrome du correcteur d'orthographe et grammatical : LanguageTool. J'utilise la version premium qui je dois dire est assez efficace. La version gratuite fonctionne également, mais avec moins de possibilités. Ce n'est peut-être pas un outil parfait même si, comme pour tout outil, ça marche mieux avec l'expérience ! ;) On essaie de rester concentré pour éviter les erreurs ! Et merci au Wiktionnaire qui précise les pluriels des mots. Cela me rend bien service de temps en temps ! ;)
J'ai pu réaliser quelques petites corrections que d'autres contributeurs ont pu rater sur la majorité des 500 pages les plus vues sur fr.wikipedia.org du mois de novembre 2020 (mais pas pour les pages les plus longues, car cela dépassait les 40 000 caractères de la version payante... Ajout d'août 2021 : on peut corriger dorénavant le début de ces longues pages et le nombre de caractères maximal est passé à 100 000 ! ;) Astuce : lorsque j'ai une page qui dépasse cette limite, j'ouvre 2 copie de la page dans mon navigateur sur mon écran que je coupe en deux. Puis, sur celui de droite, je me mets en mode "éditeur de code" (c'est plus rapide) pour ne garder que le texte que LanguageTool n'a pas pu lire (donc je supprime celui qui a déjà été traité), je me remets en mode "éditeur visuel" à droite, et je fais les corrections affichées à droite sur mon écran de gauche).
C'est à mon avis une méthode complémentaire. ;)
Mémo : messages pour les communicants[modifier | modifier le code]
Bonjour, Wikipédia n'est pas là pour faire la communication ou la publicité de quiconque. Selon les règles fixées par la communauté Wikipédia, les utilisateurs doivent citer leurs affirmations à partir de sources secondaires fiables. Vous ne pouvez donc pas inclure dans la page Wikipédia ce que bon vous semble ! Vos affirmations doivent être sourcées, par exemple, par un article du journal Le Monde, etc. En gros, nous ne sommes pas là pour créer du contenu sans source, nous essayons juste de réaliser un résumé des sources en les citant. J'aime bien la formulation de l'utilisateur Sijysuis : « Pas de sources => pas de chocolat ! » ![]() Merci d'avance.
Merci d'avance.
memo:
Bonjour, Merci de ne pas supprimer de source. Wikipédia n'est pas là pour faire votre communication. Les utilisateurs doivent citer leurs affirmations à partir de sources secondaires fiables. cf. WP:SPS
- Wikipédia n'est pas là pour faire de votre publicité ! Merci de n'ajouter que du texte avec des sources secondaire fiables. Voir [[WP:SOURCES]] + [[WP:SPS]] et en pratique : [[Aide:Insérer une référence (Éditeur visuel)]]
- Source ? Voir [[WP:SOURCES]] + [[WP:SPS]] et en pratique : [[Aide:Insérer une référence (Éditeur visuel)]]
-- Message à poster sur la pdd de l'article de l'entreprise (communicant ; contribution rémunérée)
Bonjour Notif|xxx ,
Pour parler de façon franche et directe, il y a encore pas mal de choses qui ne vont pas dans cet article (trop de textes sans sources secondaires qui pourraient être supprimés, ton non neutre à reformuler).
Rédiger un article Wikipédia n'est pas aussi simple qu'il n'y paraît. Il y a des règles et des usages. À l'heure actuelle, c'est un peu comme si on vous demandait de conduire une voiture, alors que vous n'avez pas passé de permis !
Nous avons bien conscience que l'article Wikipédia sur votre entreprise arrive en tête des résultats de Google. Donc, il vous semble normal que la qualité de celui-ci s'améliore (Ouf ! Nous aussi !).
Or, la communication telle que vous la pratiquez dans votre métier de communicant est différente sur 2 points :
1) Le fond
Quand vous publiez un communiqué de presse (ou un article sur votre site internet), vous écrivez sur tout ce dont vous avez envie (la nouvelle fonctionnalité de votre produit, votre entreprise a reçu tel ou tel prix, ...).
2) La forme
Votre style d'écriture sera de façon générale plutôt positif.
Ces deux points ne sont pas des reproches. C'est au contraire tout à fait normal et habituel dans le cadre de votre métier. Cependant, ici, les personnes bénévoles sont présentes pour écrire un article encyclopédique sur votre entreprise (Voir Ce que Wikipédia n'est pas).
Et la façon de procéder est bien différente de vos habitudes :
A) Sur le fond
Avant d'écrire quoi que ce soit, On cherche d'abord des sources. Mais pas n'importe lesquelles : des sources secondaires de qualité et indépendantes de l'entreprise. WP:SOURCES + WP:SPS. Il y a une sorte de hiérarchie des sources (par ordre de préférence) consacrées au sujet : Article universitaire ; Livre ou chapitre du livre si possible par un auteur indépendant ; Article de presse généraliste (Ex : Journaux nationaux : Le Monde, Les Echos, La Tribune... Magazines : Capital, Challenges...) ; etc.
Astuce : il est plutôt favorable que le journal cité ait déjà un article sur Wikipédia. Si c'est un journal ou magazine spécialisé, il faut voir au cas par cas (s'agit-il bien de journalistes qui signent les articles ou de simples rediffuseurs de communiqué de presse ?).
Ainsi, de façon générale, on oublie les reprises de communiqués de presse et les publireportages ; les simples mentions du nom de l'entreprise dans un article.
B) Sur la forme
Ensuite et seulement après ce travail de recherches et de lecture des sources, on pourra commencer à rédiger en résumant et en reformulant les sources et en les citant. Et là, d'expérience, le plus dur pour un communicant, c'est le Ton neutre ! WP:NdPV et WP:STYLE C'est pour cela que ce n'est pas interdit d'écrire sur la page de votre entreprise, mais plutôt déconseillé. WP:CONFLIT et WP:AUTOBIO
Ah oui, il y a bien des idées qui pourraient vous intéresser, mais elles sont en fait des "solutions" de court terme qui font perdre du temps à tout le monde et ne font pas avancer la qualité de l'article à moyen et long terme :
Pas besoin de vous énerver :
- Précédemment, toutes vos modifications sont passées et restées longtemps sur l'article Wikipédia ! WP:RCM
- Pour mon entreprise, on m'embête, alors que pour telle autre entreprise, on la laisse tranquille ! WP:PIKACHU
- Vous pouvez faire appel à une agence de communication "spécialisée sur Wikipédia" : fausse bonne idée, car un jour une personne s'en apercevra et il y aura un bandeau disgracieux en haut de l'article disant "avantage non déclaré".
- Ah ben puisqu'il faut des sources, ajouter que des sources primaires. WP:NCON
...etc.
Bref, je vous déconseille ces choix, car finalement vous risquez un blocage en écriture WP:BLOC, voire un risque de suppression de l'article et des conflits... pour rien !
Autre chose : désolé, mais personne ne peut vous garantir que le travail de recherches de sources et de rédaction neutre soit effectué, ni sous quel délai WP:PASURGENCE.
Donc en pratique, pour un début, ce que je vous propose, c'est de répondre à ce message (vous pouvez voir en haut vers la gauche que nous sommes ici sur la page de discussion dédiée à cet article) en listant quelques sources (qui vous semblent importantes et centrées sur l'entreprise) qui aideraient potentiellement à construire l'article (une partie sur l'histoire de l'entreprise et une autre sur ses activités actuelles). Par ex, max 5 de chaque.
Merci d'avance
Idée à creuser ? Essayer de quantifier le nombre d'articles dont le sourçage est amélioré par jour ?[modifier | modifier le code]
Cf. articles du Bistro : 6 novembre 2021 ; 14 novembre (fichiers dumps) ; 28 novembre 2021 (épluchage à la main sur une heure). Bon, finalement je n'ai pas de solution technique magique ! Peut-être que simplement regarder les plus gros diffs de la page modifications récentes en ajoutant les options suivantes :cf. photo (svp pas cliquer sur ce lien car sinon cela efface vos préférences de la page ! Merci à Malik) est une bonne alternative (en passant sa souris sur un diff cela donne un rapide aperçu : exemple ; pensez à ajouter le widget "aperçus de référence") ?
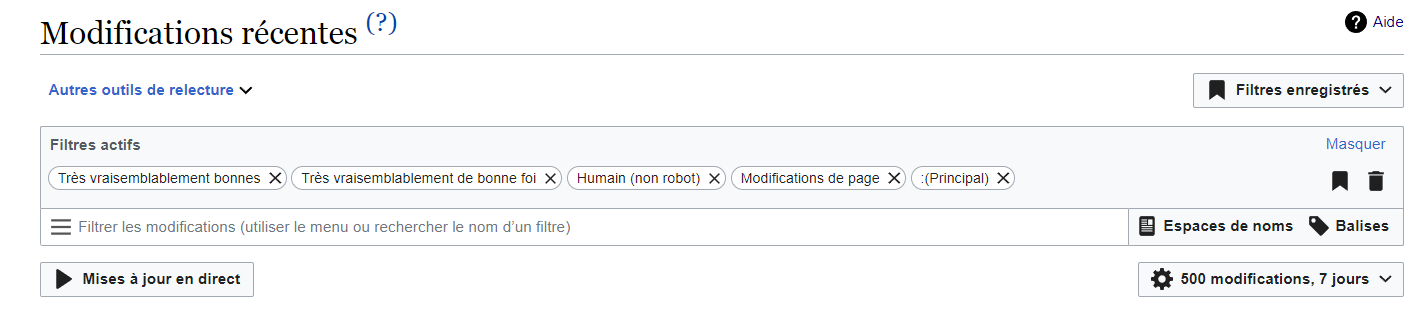{kind=link}
{kind=link}
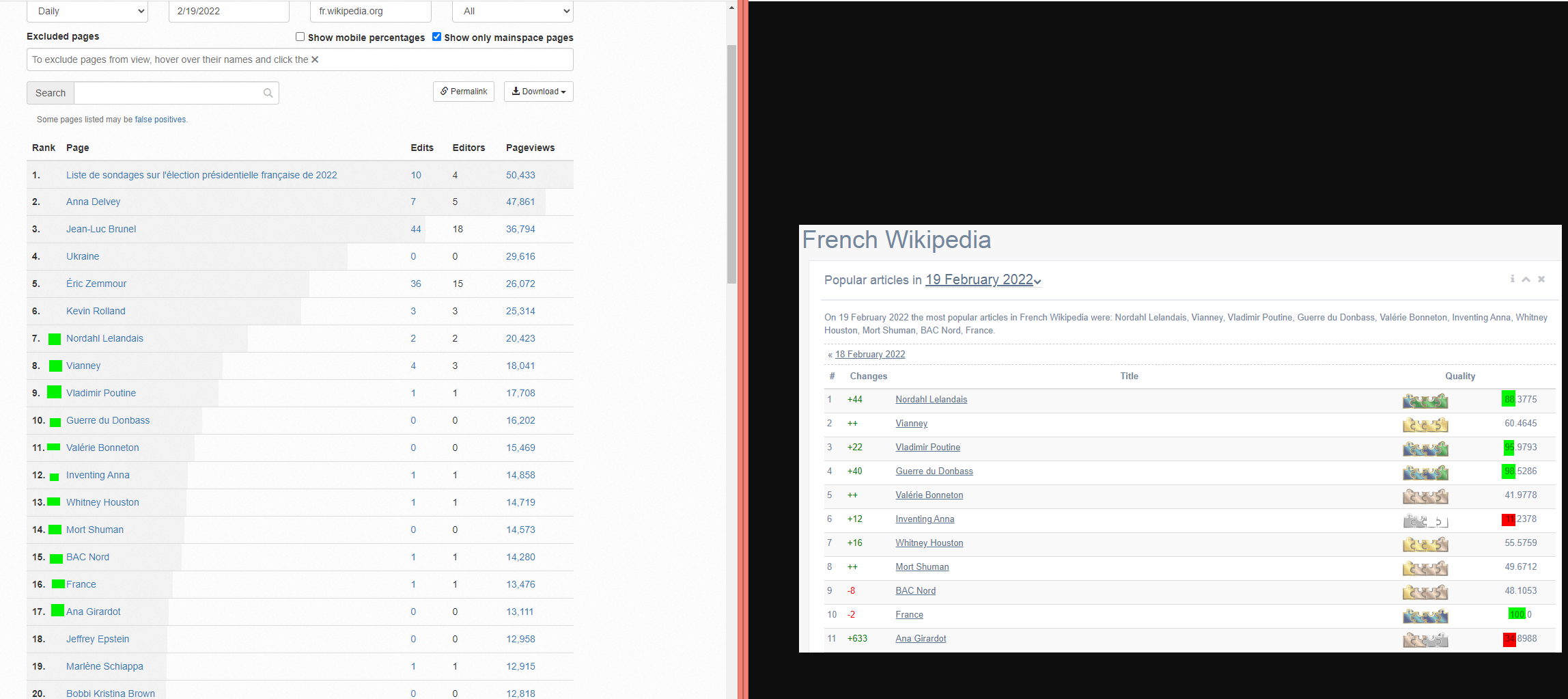
Idée à creuser ? Essayer d'améliorer le sourçage des articles les plus vus (merci Wikirank) ?[modifier | modifier le code]
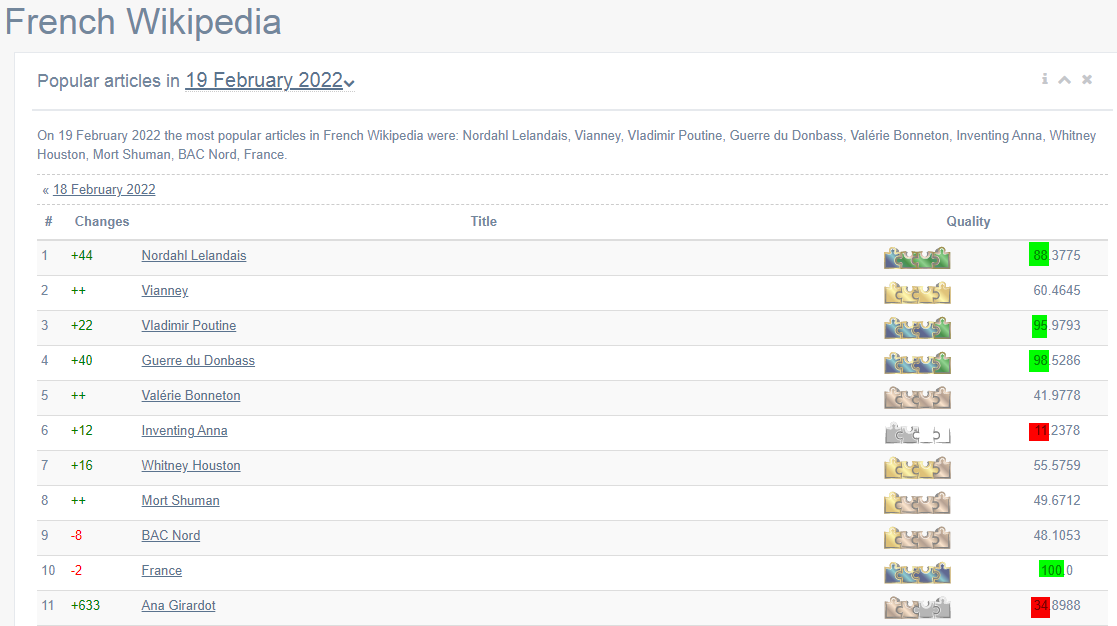
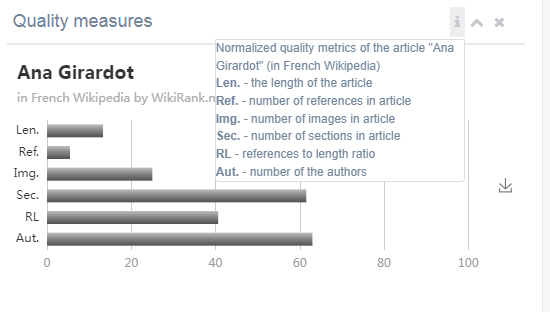
Le site Wikirank (url externe à Wikipédia -- qui est blacklistée comme "spam" par Wikipédia ! Je ne sais pas pourquoi, mais possiblement que le site n'est pas considéré comme étant fiable ?? apparemment... à cause de spams en 2020 ! Personnellement, je pense que le site est sérieux (cf. les recherches universitaires sur lesquelles il est basé) et est utile -- : wikirank[POINT]net/fr - Lien archive) propose une liste des articles les plus vus par jour avec un "indice de qualité" calculé automatiquement. cf. photo 1 pour le 19 février 2022 (j'ai mis en couleur verte les notes maximales et en rouge les minimales). Un exemple en rouge, l'indice de qualité est de 34/100 pour Ana Girardot (http://wikirank[POINT]net/fr/Ana_Girardot - Lien archive) qui était le 11ᵉ article le plus visité ce jour-là. Le site Wikirank le décompose de la façon suivante : cf. photo 2.
{kind=link}
{kind=link}
(nb: chiffres arrondis par mes soins)
Len. = Longueur de l'article (15 / 100)
Ref. = Nombre de références dans l'article (7 /100 - nb : au total, il y a 9 références dans l'article WP d'Ana Girardot)
Img. = Nombre d'images dans l'article (25 / 100 - une seule image dans l'article WP)
Sec. = Nombre de sections dans l'article (60 / 100 - j'en ai compté 17 dans l'article)
RL = Ratio : Nombre de références / Longueur de l'article (40 /100)
Aut. = Nombre de pcw qui ont participé à écrire l'article (63 /100 - 111 contributeurs selon la fiche statistiques de Xtools - Lien archive).
Score total = 34 /100 [ Soit environ la moyenne des notes (15 + 7 + 25 +60 + 40 + 63) / 6 ].
Finalement, cela reste un calcul automatique, mais je pense qu'il peut être un outil intéressant pour savoir rapidement quels articles, parmi ceux qui sont les plus vus (= lus ?), méritent une amélioration du sourçage. ![]()
Détail du calcul du chiffre 100 = meilleure valeur médiane des articles de qualité pour chaque version linguistique de Wikipédia.
"Six years ago, we proposed a method for assessing article quality on a continuous scale (from 0 to 100) using a synthetic quality score that includes normalized values (...) rule: if the value of this parameter in a given language exceeded the threshold value of the median value of the best articles in the same language version, it was taken equal to 100 points; otherwise, its value was scaled linearly to reflect the ratio of the parameter value to the mean. More detailed information about the algorithm and the results of its application of the synthetic quality index on millions of Wikipedia articles can be found in scientific publications in Informatics and Computers journal (dernier lien bloqué disponible dans la source ci- après !)." Source : 2020 Research on information quality and reliability of sources in Wikipedia par Włodzimierz Lewoniewski.
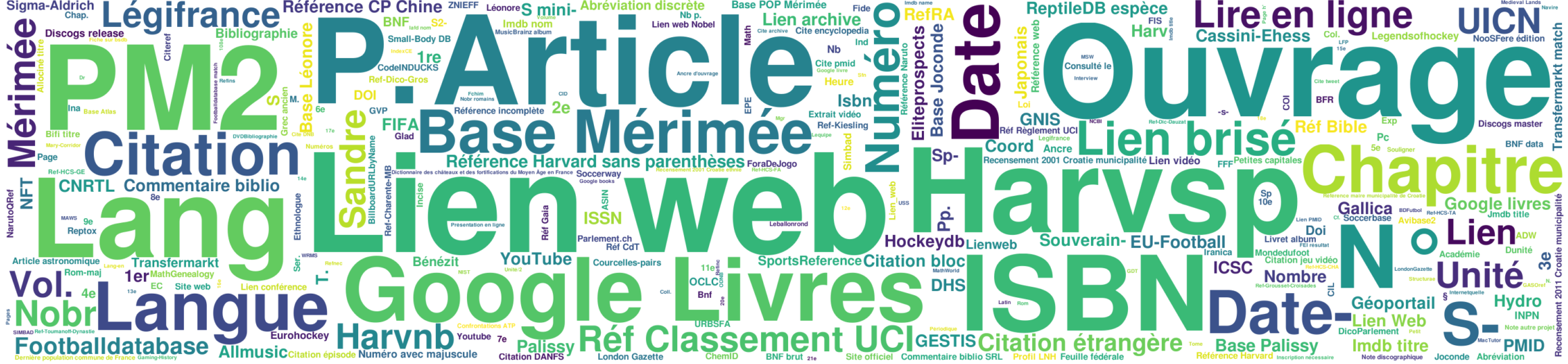
Issue de l'article ci-dessus, voici la liste des Modèles les plus utilisés dans les références présentes dans tous les articles de fr-wiki : https://data.lewoniewski.info/sources/templates/fr.png ![]()
{kind=link}
Liste des champs les plus utilisés dans les modèles présents dans fr-wiki : https://data.lewoniewski.info/sources/parameters/fr.png
{kind=link}
nb:
- L'outil de Toolforge ne donne pas les mêmes résultats pour les articles les plus vus ! : apparemment il manque les 6 premiers résultats ! C'est peut-être à cause d'un bug ? cf. photo 3
{kind=link}
- « Le trafic suit le principe de la longue traîne, le top 20 ne représentant qu’une infime part des visites de Wikipédia. Même si certains articles totalisent plusieurs millions de visites, l’essentiel des consultations sont faites par les deux millions d’articles consultés quelques dizaines, centaines ou milliers de fois par mois. »[6].
Idée à creuser ? Essayer d'améliorer les Débats d'Admissibilité (DdA) ?[modifier | modifier le code]
Discussion Wikipédia:Prise de décision/Réduire la frustration due aux suppressions
Ma démarche pour les biographies d'entreprises ou de personnes[modifier | modifier le code]
J'aime bien les biographies d'entreprises ou de personnes. Et j'essaye de les améliorer selon mes possibilités. ![]()
Voici ma démarche :
Je n'ai pas d'idée préconçue sur le contenu que je vais ajouter à l'article. Ce sont vraiment les sources que j'ai trouvées (cf. ci-dessus) qui me permettent, après leur lecture, d'écrire (façon montage de légos ou de puzzles). J'essaye de rédiger de façon neutre et d'ajouter à chaque phrase au moins une source correcte et de qualité (disons que cela fait partie des critères pour les Articles de qualité). Ah, j'oubliais, je n'ai pas de conflit d'intérêts avec telle entreprise ou telle personne sinon je n'écrirais pas dessus ou a minima, je le signalerais comme il convient.
Un petit retour d'expérience. Voici combien de temps de travail bénévole, je passe pour améliorer un article :
- quelques minutes par article pour ajouter une source facile à trouver ou utiliser Languagetool (cf. ci-dessus) pour corriger l'orthographe et/ou la mise en forme).
- environ 1 à 2 heure(s) pour un article qui est parmi les plus vus récemment et qui manque de sources (cf. Wikirank ci-dessus).
- environ 1 à 2 jour(s) de travail pour la reprise d'un article en entier, car je n'en crée que rarement. C'est peut-être la partie la plus instructive. En effet, les sources, au final souvent après dépubage, permettent de (re)construire le parcours ("dresser un portrait encyclopédique") d'une entreprise ou d'une personne de ses débuts jusqu'à maintenant. Quelle est son histoire, ce qu'elle a fait... etc. !
- environ entre une semaine et deux semaines de travail (cela ne m'arrive pas souvent, car c'est bien trop prenant !).
Je ne pense pas qu'après mon passage, la qualité de l'article soit parfaite, mais disons que j'espère que le sourçage et ma rédaction ont modestement amélioré la fiabilité de notre chère Wikipédia ! ![]()
Wikidata[modifier | modifier le code]
https://query.wikidata.org/querybuilder/?uselang=fr
https://knowledgegrapher.toolforge.org/
Les finances des fondations Wikimedia US ou FR[modifier | modifier le code]
Graphique pour la fondation Wikimédia-US : Évolution des dépenses de la fondation Wikimédia (source Wikiversity / basée sur les rapports financiers de la wikimediafoundation). Nb: il y a d'autres graphiques en français dans cette section. Évolution du nombre d'employés (en octobre de chaque année) à la fondation US : 450 (2021)[4] ; 450 (2020)[5] ; 350 (2019) [6] ; 300 (2018) [7]; (...) ; 5 (2006).
{kind=link}
Pour info, si on regarde la page 7 du rapport 990 pour la fondation US de 2020 (pdf) (source), on peut compter les 13 plus gros salaires de la wikimedia foundation US soit un total d'environ 3 millions USD. (source Bistro du 30/10/2021).
Pour la fondation Wikimédia-FR : Rapports financiers avec également les AG (ex: Présentation du rapport 2020/2021).
(source : Bistro du 16/08/2022)
Voir aussi ce tweet.
Web2cit ("collaborative automatic citations for web sources") : Corriger automatiquement les erreurs de mise en forme lors de l'utilisation du bouton « Sourcer »[modifier | modifier le code]
Voici le résultat pour un article du Figaro :

https://meta.wikimedia.org/wiki/Web2Cit
https://web2cit.toolforge.org/
Sites disponibles : https://meta.wikimedia.org/wiki/Web2Cit/monitor
Suggestions d'améliorations de Wikipédia ?[modifier | modifier le code]
Tous les ans, la fondation Wikipédia demande aux personnes contribuant à Wikipédia (pcW) leurs suggestions d'améliorations (ex pour 2021). Je me permets de recenser ici des idées (celles d'autres personnes ou les miennes - sans ordre particulier ni garantie de qualité pour ma part ! ;) ) :
- 1) Ajouter des éditeurs ou agrégateurs de presse francophone dans la carte de la Bibliothèque Wikipédia. Vu l'importance qu'ont les sources sur Wikipédia, je pensais que quelqu'un de la fondation s'en occupait. Du coup, si la disponibilité des articles en anglais est bonne (articles universitaires + presse), amha ça n'avance pas assez du côté fr pour la couverture d'archives de presse. N'hésitez pas à les contacter si vous pouvez aider. ;)
- 2) Rendre cliquable les urls ds l'éditeur visuel : souvent je suis en train de modifier un article et je dois ouvrir un autre onglet avec le même article dans sa version lecture afin de pouvoir cliquer sur le lien d'une source ou son lien archivé.
3) Ajout d'un mode prévisualisation ("preview") quand on ajoute ou modifie des images (car je trouve assez pénible de savoir si l'image choisie reste assez proche du texte ou si cela va créer un bazar visuel) ! (Voir ma proposition en 2022. Une solution dans le Bistro. Fonctionnalité refusée, car déjà existante ! Il y a déjà un mode "prévisualisation" mais il s'appelle "Relire vos modifications" (ce qui ne me semble pas adapté à l'ajout seul de photos...). On m'a également très gentiment expliqué que le problème restant (la prévisualisation ne marche encore pas très bien) allait se résoudre de lui-même dans quelque temps... ;) )- 4) « Dans la contribution à Wikipédia, les points forts d'un contributeur sont aussi souvent ses points faibles. Quelqu'un qui a des connaissances académiques d'un sujet peut avoir du mal à contribuer, car il acceptera difficilement les règles communes de contribution. De même quelqu'un qui a des connaissances approfondies des arcanes de Wikipédia peut avoir des problèmes dans son style relationnel et être trop rigide et trop cassant dans la discussion. L'idéal serait que chaque contributeur, nouveau ou ancien d'ailleurs, puisse faire un autotest sur la base du volontariat pour évaluer ses points forts et ses points faibles dans ces 4 domaines : capacité à apporter un contenu valide et de qualité, respect des formats d'édition sur Wikipédia, connaissance des processus d'administration et processus techniques, interaction fluide entre contributeurs. Le résultat de ce test pourrait figurer (toujours sur la base du volontariat) sur la page de discussion de l'utilisateur ce qui permet mieux d'appréhender le profil de la personne tout en respectant l'anonymat. Personne n'est parfait, nous sommes tous complémentaires et on a tous le défaut de nos qualités. L'important, c’est qu'on en soit tous conscients et qu'on puisse assembler sans tension qui ne se ressemble pas (c'est toute la richesse d'une communauté). Waltercolor (discuter) 23 août 2021 à 12:24 (CEST) » Source : le Bistro Mon commentaire : cela serait comme une sorte d'examen de permis de conduire optionnel. ps : lorsque j'ai sélectionné ce commentaire, je ne savais que cette personne était candidate à la Wikimedia Fondation en 2021 (finalement non élue).
5) Savoir à l'avance s'il y a des sujets présents dans l'onglet "discussion" (évite d'avoir à cliquer dessus pour rien !). Ex : je souhaite modifier un article en ajoutant des sources. J'essaye de penser à regarder la pdd, mais je ne le fais pas à chaque fois ! Car trop souvent je clique dessus pour me rendre compte... qu'il n'y a rien ! Peut-être afficher un numéro dès la page de l'article s'il y a eu une discussion récente (du genre un chiffre en gros comme lorsque l'on a un message sur Wikipédia cf. la petite cloche en haut à droite) ?(voir ma proposition en 2022. On m'a très gentiment expliqué que la proposition est également déjà dans les améliorations prévues par l'équipe d'édition. ;) )- 6) Lorsque l'on ajoute un livre avec son ISBN dans "Sourcer", le système ajoute un lien Lire en ligne, mais hélas des fois, c’est juste un lien vers Worldcat qui est un catalogue de bibliothèque ; ou c'est un lien vers seulement un extrait du livre. Bref, il faudrait pouvoir dissocier dans le modèle ouvrage (et aussi article) si Lire en ligne permet la lecture complète du livre ou juste un extrait.
- 7) Ajout plus facile directement à l'intérieur du modèle ouvrage (livre) pour ajouter des références de pages multiples.
- 8) Une fonction qui soit plus intuitive : si les ouvrages listés en bibliographie/ œuvre/publication d'un article pouvaient être listés automatiquement dans "Sourcer / Réutiliser" cela serait super ! (Voir ma proposition en 2022. J'apprends que cette proposition a déjà été faite pendant plusieurs années dans le passé (plus ou moins sous cette forme). Elle est techniquement réalisable bien que cela soit plus difficile pour l'éditeur visuel. Mais en 2021 la proposition a été abandonnée parce que... finalement, il n'y a pas tant de personnes qui ont voté pour ça ! Enfin, je me demande pourquoi on ne rendrait pas beaucoup plus facile le sourçage de livres pour tous les utilisateurs y compris les novices !)
Exemple d'une idée simple : un clic sur le bouton "Sourcer", on colle l'Isbn du livre (jusque-là ça fonctionne !) ; puis option d'ajouter une ou des pages ou un nom de chapitre ou 2 extraits de phrases pour les ebooks. Fin de l'histoire le reste est automatisable ! : ajout automatique de l'ouvrage en source ou biblio. Par la suite, si besoin réutilisation facile dans le bouton "Sourcer / Réutiliser" (sans modèle sfn à rajouter et à remplir correctement - sinon bon courage !) de l'ouvrage listé en biblio ! cf bistro du 15/01/2023. Maj du 01/02/2023 je viens de faire cette suggestion ("Community Wishlist Survey 2023/Editing").
- 9) Comment ajouter techniquement plusieurs critiques d'un ouvrage (recension) ? (proposé en 2022 sur la pdd concernée)
- 10) J'ajoute la même source dans une infobox sans qu'elle apparaisse plusieurs fois dans la liste des références (quelqu'un me l'a déjà montré, mais je ne m'en souviens plus !).
- 11) Pas de raccourci facile direct dans la barre de menu pour le modèle ouvrage. D'ailleurs il n'est pas forcément évident de comprendre tout de suite que le mot ouvrage signifie livre amha.
- 12) Savoir où en sont les suggestions de nouveaux partenaires de la Wikipédia Library. (Ma proposition 2022. L'équipe de la bibliothèque Wikipédia va bientôt essayer de tenir à jour le suivi des demandes de suggestions de nouveaux partenaires. ;) )
- 13) Gadget "Who wrote this" bientôt sur fr-wiki ?
- 14) Possibilité d'ajouter 2 urls quand une source est nativement découpée en plusieurs urls (ex une page = un fichier pdf). C'est toutefois rare...
- projet Web2Cit (cf Bistro) : amélioration du bouton sourcer/automatique avec suggestion de mise en forme optionelle.
Merci à la communauté pour ces améliorations (je n'y suis pour rien ! ) qui ont déjà été effectuées et celles en cours ! ;) :
- on peut s'abonner à une discussion afin de la suivre
- la fonctionnalité répondre qui non seulement permet de répondre sans se préoccuper d'ajouter ou non des ":" pour indenter la conversation, mais également alerte la personne à qui vous répondez. ;)
Bon courage à tous et régalez-vous ! ;)
Références[modifier | modifier le code]
- « 280. Gallica répond aux Gallicanautes – Paroles d'histoire » (consulté le )
- « Au cœur d'Internet Archive : l'archivage du web ! » (consulté le )
- webcorpora, « Regards croisés sur les outils d’accès à la BnF et à l’Ina », sur Web Corpora (consulté le )
- « Comment les archivistes de la BNF sauvegardent la mémoire du confinement sur Internet », Le Monde.fr, (lire en ligne, consulté le )
- « Le web du grenier est bien conservé à la BNF », sur www.franceinter.fr, (consulté le )
- Pierre-Yves Beaudouin, « Articles Wikipédia les plus consultés en 2020 », sur Wikimédia France, (consulté le )